Doing an IAmA
Google voter info gadget
Today Google launched a voter information mapplet and gadget that I built (with help from some talented people at Google).
It’s a simple little application that just looks up voter registration information for your address, and later this month will also display your voting location. They are going all out to promote it, with a link on the main Google home page, and a cool video with a few faces you may recognize:
Now go register to vote, or Leonardo will never speak with you again!
Annotate your YouTube video with AnnoTube
AnnoTube is a jQuery plugin that makes it easy to embed a YouTube video in your page along with an index and notes that are displayed and synchronized with the video as it plays. Each note can be an HTML snippet, or a URL to be loaded into an IFRAME, or even a JavaScript function to be run when a specific time in the video is reached.
Here’s a demo: the Mapping the Votes talk I gave at Google in April, with annotations provided by AnnoTube. This solves a mistake I made in this talk: Like many speakers, I left the text too small in my code examples. It looked fine to the people in the room, but the code is really hard to read in the YouTube video. But with the annotations I can put big, readable text right next to the video at the right time.
Fair warning: At this moment, I’ve only annotated the first 15 minutes of the video, and all of the notes so far are actually web pages in an IFRAME. Also, the AnnoTube plugin itself isn’t quite ready for general use. This is all a bit of work in progress, which started with something I put together for fun during the Google I/O conference. I’m only posting now because the YouTube API team is mentioning it in a post of their own, so please watch this page for updates over the next few days.
For a start, here’s what the timeline for my talk looks like (with URLs shortened to avoid long lines):
As you can see, it’s just a simple list of times, titles, and links or HTML snippets. AnnoTube takes care of connecting the events and watching for the times you specify.
More details soon… Thanks for your interest and patience!
Pennsylvania Primary Google Map
Another day, another primary, another Google map. This time we added a bunch of demographic information using little sparkline graphs, with help from Jim Barnes of the National Journal. I think the voter registration by age is especially interesting. Check it out:
(The map probably won’t load in an RSS feed, so click through to the article to see it.)
You can get this map for your own site!
Mapping the Votes - resources
I want to thank everyone who came to my Mapping the Votes talk at Google. The talk is available on YouTube - with apologies for the small font size in the code samples!
Here are some links and information that I referred to in the talk.
Maps and mapplets
Decision 2008 - the current election mapplet
Decision 2008 Gadget - the election map as a Google Gadget
Iowa Republican Caucus - an early API map
Iowa mapplet - an early mapplet
Twitter election map - the Super Tuesday twitter map (showing tweets from that day)
Campaign Trail - candidate calendars
New Hampshire in Google Earth - a KML file
Editors and desktop tools
The editor I used for the code samples is the one I use every day, Komodo IDE. Komodo’s debuggers for Ruby, Python, and PHP make it really easy to test my batch/script/server code. I’m especially fond of coding in the debugger. For the code that converts shapefiles and vote data into JSON output, I’d write the input part first, set a breakpoint and stop in the debugger after it reads the data, then write the conversion code with live data to look at while I code. Komodo also has a JavaScript debugger that works equally well, but most of the time I just use Firebug because of its simplicity.
Komodo IDE isn’t cheap, but I figure it paid for itself really fast. There’s also a free Komodo Edit that everyone should install even if you already have a favorite editor. Both versions have real-time syntax checking, where you get squiggly red underlines for syntax errors and squiggly green underlines for warnings, just like the spelling and grammar checkers in a word processor. This has saved me literally thousands of page reloads when testing, since Komodo catches my syntax errors before I even save the file. Komodo runs on Linux, Mac, and Windows.
One nice thing about GUI editors is that the basic editing works the same in all of them (or should), so it’s easy to switch back and forth if some other editor has a feature you want to take advantage of. Besides Komodo, I also use PSPad (free, Windows only), mostly because of its nice HTML/XML pretty-printer. It cleans up unreadable web page source code real quick.
Another expensive-but-well-worth-it tool for Windows and Mac is Araxis Merge, a terrific file compare and merge program with live editing. I use Merge as the diff/merge program for TortoiseSVN, which makes source control a dream.
A couple of free Windows tools I use every day are Zoom+ for screen zooming and my own JKLmouse for precise cursor control with the keyboard of your notebook computer. With JKLmouse, I can use the TrackPoint for fast cursor motion and then the keyboard for fine pixel-by-pixel movement, seamlessly and with no “modes”. (Sorry, I had to brag!)
Source code
The election map code is open source and is in two Google Code projects. The current code is in the primary-maps-2008 project, and the code for earliest caucuses and primaries is in the gmaps-samples project. (We moved the code to a new project to avoid filling up gmaps-samples!)
If you look at the code, go easy on me: much of it was written under severe time pressure. I asked if the elections could be delayed when I wasn’t quite ready, but even the mighty Google couldn’t seem to arrange that.
Also, if you read the code using the links provided here, there’s an awful lot of indentation, thanks to Google Code displaying my tab indentation using 8 spaces per tab. Shades of K&R! (So, why do I use tabs instead of two-space indents like everyone else? Well, one of the other benefits of Komodo is that unlike most code editors, it lets me edit in a proportional font. Two spaces in a proportional font is almost like not indenting at all.)
Shapefiles
Shapefiles are a wacky file format  used for geographic data. Be thankful that other people have already written programs to pick them apart, so you and I don’t have to.
used for geographic data. Be thankful that other people have already written programs to pick them apart, so you and I don’t have to.
At first, I was using shp2text to convert shapefiles to an easy-to-use XML format (using the --gpx option), but this loses some of the information in the shapefile. More recently, Zachary Forest Johnson, author of the interesting indiemaps blog, wrote shpUtils.py, which decodes shapefiles into usable Python data.
I extended shpUtils.py to calculate correct centroids, area and other information about the shapes, and to fix a few bugs. The updated version is in the primary-maps-2008 project.
Centroids
The election maps use the centroids of the state and county polygons to position markers for those states.
Centroids are one of those things that you think you understand and then find out you were completely wrong. My first guess was the same as Zachary’s, to take the arithmetic mean of all the points (X and Y separately). The Wikipedia article even seems to say this, but it’s talking about the centroid of the points, not the centroid of the polygon that those points define. If you read it carefully, the article does give the correct algorithm, but it’s better explained on this page, along with sample implementations in various languages.
Census bureau shapefiles
The state and county outlines in the election maps come from shapefiles provided by the Census Bureau. Most states report votes by county, but a few New England states report by town (County Subdivisions in the Census Bureau page), and a few other states report by congressional district.
Shapefile simplification
D’oh! I completely forgot to talk about this important topic. The Census Bureau shapefiles have too much detail to be usable in a browser-based map. If you draw polygons from them, it will be much too slow. A tile layer can handle more detail, but the graphic files will be larger than they could be, because of the excess detail.
MapShaper is a free online tool to simplify shapefiles. It is pretty neat—you can see the effect of your simplification in realtime as you try different settings. I used MapShaper for the election maps, with various levels of simplification: simpler for JavaScript and more detailed for tile layers. More recently I discovered the Map Simplification Program which looks ideal for programmed simplification.
The code that processes shapefiles for the election maps is in makepolys.py which generates JSON output, and maketiles.py which generates tiles from that JSON data using ImageMagick.
Votes and delegates
The code to convert vote data from the latest primaries is in voter.py. This processes CSV files provided by the Boston Globe and converts them to JSON data.
Twitter map
The Ruby script that gathers the Twitter updates uses the Jabber::Simple module written by Blaine Cook to create a custom Jabber client that talks to Twitter, and uses the Twittervision API to get geographic information. It parses the XML data with sweet Hpricot, then generates JSON data (but you probably saw that coming). If you like jQuery, you’ll like Hpricot.
Mapplet code
The election mapplet code is in decision2008.xml and map.js. The code for the Campaign Trail mapplet is in campaign-trail.xml and campaign-trail.js. The latter file has the latest versions of the Array.mapjoin(), Array.index(), Object.sort(), S(), and related functions that I talked about. They are at the top of the file, and not yet documented, but you can find examples of each in the code.
More to come
That’s it for now! I’ll be posting more detailed articles on some of these topics. If there is a particular area you’re interested in, please let me know in the comments.
Thanks!
Google Maps talk
Update: I posted some notes and links from the talk.
I’m giving a talk at Google tonight at 6pm about the election maps I’ve been working on. I’ll be talking about:
- How to use the same code for a mapplet, a Google Gadget, and a Maps API map
- Turn shape files into map tiles, polygons, and markers
- Collect voting results into JSON objects
- Marker madness - can we make it fast enough?
- Hosting on Google Code and Amazon S3
- A custom Twitter map using Jabber to track keywords
I’ll follow up tomorrow with links to the resources I mention in the talk, and then will post a series of articles going into some of the topics in more detail. If you are at the talk or watch the YouTube video, let me know in the comments what areas are of most interest for follow-on articles.
To register for the talk: https://sv-gtug-4.eventbrite.com/
Thanks!
My little Google map
I’ve been working on a project for Google this last month, a mapplet with primary election and caucus results. We’ve done different versions for the primaries so far. For previous states, the emphasis was on mapping the county-by-county results. The latest one is different, a bit of a Twittervision clone, but filtered for messages related to the elections instead of all Twitter messages.
Some people said it was lame and useless; others complained that they spent all day Tuesday watching it.
We report, you decide. :-)
There are plenty of stories to tell about this project, more later…
MakeProcInstance
Wow, this was a blast from the past. Raymond Chen reminisces about a 16-bit Windows function, MakeProcInstance.
Thanks, Raymond, I think! I’ve been trying to forget the horror of 16-bit Windows programming. Be thankful that you don’t have to work with it, and neither does anyone else. :-)
Social Scripting from IBM
Here is a script from IBM’s new CoScripter, to update your Facebook status:
It reads just like the instructions you might write down for someone, but it’s an actual executable script. All the scripts are stored on a wiki so anyone can share and update them.
Very interesting… And definitely not your grandfather’s IBM.
Via Jon Udell.
Two letter domain? No cookies for you!
This is too strange to believe, but it is true.
I’ve noticed that it is impossible to log in as a registered user here at mg.to using Internet Explorer, even though other browsers work fine.
Now I know why:
Internet Explorer does not set a cookie for two-letter domains (Microsoft Knowledge Base)
IE and 2-letter domain-names (crisp’s blog)
That's not a tax, it's a federal grant

From the San Jose International Airport Fact Sheet:
No tax funds are used for the operation nor development of the Airport. Airport revenues come from user fees and federal grants.
And where do the federal grants come from?
Google adopts my GAsync() API
Ben Appleton of the Google Maps API team posted today that Google has added my GAsync() function to the Mapplet API. I don’t see the function listed in the Mapplet API documentation yet, but it should be there soon.
In the meantime, you can read my post that describes the API and how to use it.
One thing not mentioned in Ben’s post: you can use GAsync() not only to improve your mapplet code, but also to write common code for both a mapplet and a regular Maps API application. To do this, you will probably need to include the GAsync() source code in your application—I don’t know if it’s been made part of the standard Maps API.
Thanks Ben and the Maps API team!
Write the same code for Google Mapplets and Maps API

My last post introduced a new GAsync API for Google Mapplets. I wrote that code to speed up the response time in our new Zvents mapplet. Try out our mapplet—it’s a fun way to discover things to do in your area.
Naturally, I was barely done with the mapplet when the thought came, “Could we use this same code as a Maps API application?” The two APIs are mostly the same except for initialization—and the pesky matter of the Async calls, e.g. map.getCenterAsync() in the Mapplets API vs. map.getCenter() in the Maps API. But having already written the GAsync code, it turns out to be easy to make it work in both a mapplet and a Maps API app. The interface to GAsync doesn’t change at all from the previous version. The only difference is that the function now calls either the Async functions in a mapplet, or the non-Async functions in a Maps API app. And at the end of the function, for the Maps API it calls your callback function immediately—there’s no need to wait for any asynchronous calls.
You still have to write code in the mapplet fashion, with a callback when you want to retrieve information from the map—but now you can write code like this and run it identically in a mapplet or a Maps API app:
Additional code samples are in the original article.
Here is a demo page running the test mapplet from the previous article as a Maps API app.
And here is the updated GAsync code. First, a compact version ready to copy into your mapplet + Maps API code:
And a commented version:
As the code says, enjoy!
A fast and simple async API for Google Mapplets
Update 2007-06-22: Version 2 now supports portable code that runs as both a mapplet and a Maps API app. Read about the update.
If you’re building a Google Mapplet that responds to map movement and resizing, you will soon find yourself writing code like this recent gem of mine:
What is going on here? I have a search() function that takes the current map size, bounds and center, runs a search and displays pins on the map. In a normal Google Maps application I could have simply coded:
But a Google Mapplet lives in a strange and different world. To isolate mapplet code from the Google domain, Google runs the mapplet in an IFRAME loaded from the gmodules.com domain. Cross-domain browser security prevents your code from communicating directly with the Google Maps frame loaded from maps.google.com.
The mapplet API uses the iframe fragment hack to allow limited communication between the mapplet and the Google map. This has two consequences:
The communication is asynchronous. This doesn’t affect the API for functions that simply set map state—they operate on a “fire and forget” basis. But functions that return information can’t do it directly. You have to provide a callback function that receives the information when it is ready.
The communication is slow. Everything is serialized through the fragment identifier (hash) of a hidden IFRAME. The map page and the mapplet frame each have interval timers running to watch for changes to this hash. A single
getSomethingAsync()function call requires all these steps:- Mapplet frame sets the hash to represent the function call.
- Map page timer wakes up, makes the actual Maps API call, and sets the hash to represent the return value.
- Mapplet frame timer wakes up, gets the value from the hash, and calls the callback function.
My code listed above makes three of these round trips to the maps page one after the other, because the callback for each function triggers the next step in the series. That’s a lot of timeouts—enough to cause a noticeable delay.
What if we could somehow combine all three information requests into a single round trip? That should speed things up quite a bit. Imagine a different Mapplet async API where you provide a list of Maps API functions and get back all of their responses in a single callback with multiple arguments. My three nested function calls and callbacks could be reduced to:
(The sharp-eyed reader will note that the search() function could be used directly as the callback because it takes the same arguments:
But we’ll stick with the longer form for this discussion, because it makes it clear what the function arguments are.)
While we’re at it, we can provide a way to retrieve information for more than one object in a single call:
And for functions such as map.fromContainerPixelToLatLngAsync() which take an additional argument, we can allow an optional arguments array after any function name:
Compare that with the equivalent nested functions using the existing API, which would take about three times longer to run:
Good news: We don’t have to wait for Google to implement this zippy GAsync API or something like it. Although the public API only exposes individual xyzAsync() functions, the underlying iframe fragment dispatcher can queue up multiple function calls and return values into a single round trip.
The Google Maps team was kind enough to provide me with a nifty makeBarrier() function that allows us to queue up a number of async calls and get a single callback when all their values are ready. Using this function, my first example can be written as:
As you can see, it’s up to us to count the functions and keep track of the values, but having done that, we can get all three values in a single round trip through the API. It’s literally three times faster than the nested API calls.
Armed with that information, could we code GAsync() as a layer on top of the existing mapplet async APIs? Indeed we can!
You can try out the code right now and see the speed difference with my test mapplet. Go to the Google Maps Developer Preview page, log into your Google account, and click the Add Content link under the Mapplets tab (or click the Browse Content button if that is what is there).
The next page will show a number of existing mapplets. Click the tiny Add by URL link next to the search button at the top of the page, and paste this URL into the URL box that opens up. You can also click this link to see the mapplet source code:
https://mg.to/mapplet/async/async.xml
(When you paste the link, make sure the https:// isn’t duplicated because of the text already in the box.)
Click the Add button and click OK on the confirmation dialog. Then click Back to Google Maps at the top left corner of the page, and you should see a new entry titled A fast simple mapplet async API. Click it to load the mapplet.
An info window should open in the map, displaying several items of information about the map, and the time it required to collect the information using the GAsync() API. Then try the Slow Async API radio button to see the performance using nested async calls.
The GAsync code used in the test mapplet is:
and the corresponding nested async code is:
Finally, here is the GAsync source code. First, a compact version suitable for pasting into your own mapplet (or download async.js):
And a heavily commented version that explains how it works:
Of course, there are still cases where you will have to run one async call after another one. If you need one piece of information as input to a subsequent call, nested async functions are the way to do it. Even then, it may be possible to combine some other async calls into a single GAsync call, wherever they don’t depend on each other’s results. You’ll shave about a quarter second off your mapplet’s response time for every call you combine using GAsync.
Enjoy your simpler and faster mapplet code!
Thanks to Ben A. of Google for mapplet design and coding tips.
An email panic button
Today’s USA Today has an interview with David Shipley and Will Schwalbe, the authors of Send: The Essential Guide to Email for Office and Home. The article has some good tips, but one remark caught my eye:
They say one thing everyone wants, but no one has invented, is a “panic button,” a short delay after hitting send, like the kind TV networks use to bleep obscenities.
If you’re using Microsoft Outlook, it’s easy to set up a sending delay. I’ve been using one for years. I don’t usually put obscenities in my emails, but it sure is handy for the many times that I’ve forgotten to include an attachment and remembered right after hitting Send.
The feature is fairly well hidden, so Shipley and Schwalbe can be forgiven for not knowing about it. Here is how to set it up in Outlook 2003. The exact steps will vary in other versions of Outlook, but it should be similar.
- Starting on the main Outlook window, open the Tools menu and select Rules and Alerts…
- Click the New Rule… button.
- Click the Start from a blank rule radio button.
- Under Step 1, click Check messages after sending.
- Click Next >
- Don’t select any of the conditions in the list. Click Next >
- A message box will warn that “This rule will be aplied to every message you send. Is this correct?” Click Yes.
- Click Next >
- Under Step 1, click the defer delivery by a number of minutes checkbox.
- Under Step 2, click a number of.
- A dialog titled Deferred Delivery will open. Choose the number of minutes you want to delay outgoing email and click OK.
- Click Next >
- Don’t select any of the exceptions in the list. Click Next >
- Enter a name for the rule, such as Defer Sending.
- Click Finish.
With this rule enabled, when you send a message, it will remain in Outlook’s Outbox for the number of minutes you specified. You can open the Outbox, open your message, and edit it before sending again. The same time delay will apply again.
Beware of one annoying Outlook bug: Depending on what add-ons are installed in Outlook, you may find that after you edit a message and re-send it, it remains in the Outbox and does not get sent at all. You’ll notice that the message in the Outbox list was italicized before you re-edited it, but after sending it the second time it is no longer in italics. This is Outlook’s subtle hint that it is not going to send the message at all!
To work around this, open the message from the Outbox, and before you re-send it, select any other folder in the main Outlook window. Then you can send the message and it will go out as expected. (If you’re curious, after resending the message, you can check the Outbox again and you’ll see that it is italicized, indicating that Outlook will send it after all.)
JKLmouse: the automatic keyboard mouse for notebook computers
Have you ever wanted to use the mouse to move something with pixel perfect precision? There is a way to do it: a “keyboard mouse.” One good one comes with Windows, called MouseKeys. If you’re using a desktop computer with a dedicated numeric keypad, you can turn on MouseKeys and leave it on, then use the numeric pad to move the mouse in any direction one pixel at a time.
Unfortunately, MouseKeys is barely usable on a notebook computer. You can get it to work, but you’ll have to turn it on and off all the time because it prevents normal use of the keyboard—the “numeric pad” on my ThinkPads and on most other notebooks is overlaid on the QWERTY keyboard.
So I wrote JKLmouse, the automatic keyboard mouse for notebook and laptop computers. JKLmouse doesn’t use any special modes—it is always active—and it doesn’t interfere with normal use of the keyboard.
The secret is simple: JKLmouse turns keyboard keys into mouse movement keys only while a mouse button is held down. When no mouse button is down, the keyboard works normally. When any mouse button is down, you can use the cursor arrow keys to move the mouse, and you can also use keys on and around the home row: JKL for the right hand or SDF for the left, along with the keys above and below those.
This works especially well on a ThinkPad, where the TrackPoint is also right next to the home row. You can start moving something with the TrackPoint, then continue to hold the mouse button down and use JKL and nearby keys to move the last few pixels, one pixel at a time. There’s no special “keyboard mouse” mode—you can combine TrackPoint and keyboard movement seamlessly. It also works fine with touchpads—just keep the mouse button down and you can use either the touchpad or the JKLmouse keys.
What if you want to use JKLmouse without holding a mouse key down? Hold down the Caps Lock key and you can use all of the JKLmouse keys while Caps Lock is held down. This won’t turn on the Caps Lock mode and doesn’t interfere with normal use of Caps Lock.
I wrote JKLmouse for my own use because I wanted a keyboard mouse that Just Works on my ThinkPad, without the special modes that other keyboard mice use. I’ve found it tremendously useful and I hope you enjoy it too.
JKLmouse runs on Windows 95, 98, 98SE, Me, 2000, and XP. I haven’t tested it on Windows Vista yet. See the download page for more details:
Enjoy!
We are not evil, and we will burn down your church to prove it
I’m a big fan of The Daily WTF, even if I can’t explain its name in mixed company. But today the real world has outdone anything that site ever posted.
You see, the Pope gave a speech that quoted a 14th century Byzantine emperor who said that Mohammed’s teachings were “evil and inuhuman”. Naturally, some people took offense. No one likes to have their faith criticized, and a few people decided to prove that emperor wrong. To demonstrate their lack of evil, they burned and shot up a few churches.
WTF?
Seth Godin, read "I, Pencil"
Seth Godin is one of the smartest marketing guys around. But he seems misinformed about economics.
In his article No stoplights, Seth says:
While individuals might moan about how they were treated, we all realize that without some sort of central allocation of scarce resources (like a piece of tarmac or a booth at a trade show), chaos ensues. And the chaos hurts everyone.
Well, no. Consider the lowly pencil. Cheap, effective, ubiquitous. But nobody knows how to make one. Nobody.
There is no one person on Earth who knows how to find, process, and assemble all of the materials that go into a pencil. A lot of people know their own parts of the puzzle, but nobody knows the whole thing.
No central allocator. But somehow pencils get made, and plenty of them.
Leonard Read can explain it better than I can:
Now, if nobody knows how to make a pencil, how could anyone centrally allocate all of the scarce resources needed to make one? How in the world would they know what to allocate?
And watch out. If you do get that central allocator, it will turn out to be somebody who believes:
A pencil factory is not a big truck. It’s a series of tubes.
And if you don’t understand those tubes can be filled and if they are filled, when you put your lead in, it gets in line and its going to be delayed by anyone that puts into that tube enormous amounts of material, enormous amounts of material…
Prince Tu'ipelehake and Princess Kaimana, R.I.P.
When I tell people the address of my blog, they sometimes ask me, “mg.to? Huh? What’s .to?” I explain to them that it is the country code domain for the Kingdom of Tonga, but .to names are open to anyone, and I registered the name because it was fun to have such a short domain name with my initials in it.
Even with that small connection to Tonga, I was deeply saddened to read of the deaths of Prince Tu’ipelehake and Princess Kaimana and Vinisia Hefa. Prince Tu’ipelehake was on a tour speaking at several Tongan churches in the Bay Area, when a teenage driver who was racing on Highway 101 hit their Ford Explorer, which then overturned.
My prayers and condolences to the royal family and the Tongan people.
Prototype vs. Web 2.0
In yesterday’s Ajaxian, Rob Sanheim reviews a post that explains why programmers should not use JavaScript’s Array type for associative arrays. Array objects should be used only for integer-indexed arrays. The correct type for an associative array in JavaScript is Object, not Array.
Rob is right, of course. A JavaScript Object is an associative array or hash table. An Array is also an Object (in fact, typeof [] == 'object'), but it’s really meant for arrays indexed by integers.
It’s an easy mistake to make, especially for someone who has come from a language where the associative array type is called an array. I don’t think I’ve made this particular mistake, but I have made a similar one. I used to use the for-in loop because I liked its simplicity:
That looks better to me than the C-style loop:
The for-in loop works on an Array because an Array is an Object, but that also means it treats the Array as an Object. It enumerates the array elements because they are also properties of the underlying Object, but it doesn’t necessarily enumerate them in order by index:
In the browsers I tried, this code alerts the letters in the order that they were added to the array, not in index order. But there’s no guarantee about that order either, because the for-in loop doesn’t promise any particular order of enumeration.
Worse, for-in also enumerates any extra properties or methods added to the array:
This alerts the source code for the alert method as well as the three letters in the array, because they are all properties of the underlying Object.
The same thing happens if the alert method is added via Array.prototype:
And that’s where we get into trouble with Prototype, because it adds methods to Array.prototype. This breaks any code that uses for-in on an Array. But as we just discussed, no one should do that, so it won’t be a problem in any properly-written code. Right? Case closed.
The other problem with using Arrays as associative arrays means you can no longer extend
Array.prototype, which is what Prototype 1.5 does to great effect. Prototype did break Object associative arrays in 1.4 with additions to Object.prototype, something that is fixed in 1.5 after much wailing and gnashing of teeth. Some might argue extending any of the built-in objects’ prototypes is bad form, but those people are wrong.
I wouldn’t argue that it’s bad form, but extending the native object prototypes causes real pain for two groups of people:
People who write JavaScript widgets to be used on other websites, and
People who use third-party JavaScript widgets on their sites.
It’s that whole Web 2.0 mashup thing, you know?
As a widget author, if I use Prototype, then sooner or later one of my customers will want to combine my widgets with JavaScript code from somebody who does use a for-in loop on an array—“correct” or not. Or code that uses some other library that also extends Array.prototype—even a different version of Prototype that conflicts with mine.
I love the good taste of syntactic sugar as much as anyone, and if it didn’t break other code I’d be merrily adding methods to the native objects too. But I have to make my code compatible not only with the code I control, but the code I don’t. So it’s no Prototype for me.
Best news interview ever
Is Jesus the next killer app?
Your <body> is in your <head>
I was chasing down a bizarre bug. My JavaScript code was working fine in IE, Firefox, and Safari, until I tried using it here on mg.to. It still worked in Firefox and Safari, but it blew up in IE, with behavior that made no sense at all. I was seeing duplicate copies of DOM elements I created using my DOM creation plugin for jQuery, and all kinds of strange behavior. It was almost as if something was fundamentally wrong with the way the DOM was working.
I’m usually pretty good at tracking down problems, but this one had me stumped. I wanted to look around the the DOM structure, but since this was IE, I couldn’t use any of the usual Firefox plugins such as the DOM Inspector or FireBug. Then I found a great tool for IE troubleshooting, the DebugBar.
I looked at the DOM with the DebugBar, and my jaw dropped when I saw this:

(This screen shot and the others below are from simplified test cases.)
This had to be impossible! The document <body> was inside the <base> tag, which in turn was inside the <head>. The latter I’d expect, but why was <body> not a sibling of <head> as it should be? And how was <base> involved in this?
I got lucky with some searches and found these articles by Justin Rogers from the IE team:
This part of the “Implied tags” article seemed to explain what was going on:
The set of implied rules has impacts in other areas as well. You can, for instance, end up using document.writeln to prematurely terminate your HEAD element and move a bunch of stuff out into the BODY. So, if you are doing inline document writes you should probably do them where you want the content to go. Writing the content out in script blocks that appear in the head is the wrong way to go about it. You could hook up to some events or have a container element that you write into, and that is acceptable, but with inline writes you could get unexpected behavior.
Recently I noticed a site that was doing a document.writeln in their HEAD element about half-way through the head content. End result? Well, the content got moved into the BODY element and the object model tree for the page was completely wrong. Good thing they weren’t navigating the object model looking for stuff and good thing the extra META/LINK elements weren’t being used as well. With a static parse of the page you wouldn’t even notice these problems, but when DHTML becomes involved it can change the structure of your document on the fly and rewrite what the object model tree looks like.
Indeed, this site runs on Drupal, and Drupal 4.6.x does use a <base> tag. (The forthcoming Drupal 4.7 eliminates the <base> tag.)
Justin’s examples showed an unclosed <base> tag like this:
That should be OK; the W3C HTML specification defines the BASE element as EMPTY, so it shouldn’t require any kind of closing tag (except for XHTML compatibility).
The <base> tag that Drupal generates is self-closing in the XHTML style:
However, IE6 does not seem to recognize that the tag is closed (or EMPTY), and it puts everything after that inside the BASE element.
(You may also notice that strictly speaking, Drupal’s <base> tag is incorrect. It should include a filename, but it seems to work OK without it—except for the IE problem.)
On a hunch, I tried closing the tag the old fashioned way:
and presto! Everything started working, and DebugBar revealed that the <head> and <body> elements were siblings, both direct children of <html> as expected.
The bottom line: Every HTML document in the world that uses a <base> tag is being parsed in this odd way by IE, unless an explicit closing </base> tag is used. It doesn’t affect ordinary HTML rendering, but any kind of DOM manipulation may go haywire.
Here are the three test cases. First, the unclosed/empty <base> tag:

The XHTML-style <base /> tag is no better:

And the one that works, with a closing </base> tag:

There is one remaining problem. If you validate your pages as HTML 4.01 Transitional, there is no way to use a <base> tag that works correctly in IE and also validates. The validator barfs on the closing </base> tag, because it figures the tag is already closed (being an EMPTY element).
If you use XHTML 1.0 (either Transitional or Strict), then you can use the closing </base> tag and it will validate. Since most people who validate their pages are probably using XHTML anyway, this shouldn’t be a problem for many.
However, the W3C’s XHTML/HTML Compatibility Guidelines offer this warning:
…use the minimized tag syntax for empty elements, e.g.
<br />, as the alternative syntax<br></br>allowed by XML gives uncertain results in many existing user agents.
Well, that’s just great. The only syntax that works in IE and validates is <base></base>, but W3C warns against it. I haven’t actually seen any problems caused by using this syntax with the <base> tag, though, even in old browsers. So for now, I’m using it and hoping for the best.
Major thanks are due to the DebugBar for pointing me toward the problem, and Justin Rogers for explaining it.
Google Romance uses ThinkPad X41 Tablet
Feeling lucky?
Thanks to Google’s new Contextual Dating service, the ThinkPad X41 Tablet PC can help!

DOM creation: good, bad, and ugly
The Ajaxians are talking about a new $E function that is supposed to make it easier to create DOM elements. The example given creates the equivalent of this HTML code:
using this code to do it:
That seems just a tad complicated! Let’s see how it would look using my DOM creator for jQuery and Prototype:
Ah, that is quite a bit simpler. It’s also more flexible. Suppose you want to save a reference to that A tag in the middle. There’s no way to do that with $E, but it can be as easy as this:
San Jose Snow
The view from my balcony this morning. Do you see the birds?

Easy DOM creation for jQuery and Prototype
Here is a jQuery plugin that makes it easy to build up a tree of DOM nodes. It lets you write code like this:
Basically, each function such as $.TABLE creates a DOM node and takes the following arguments:
The first argument is an object that list any attributes to be set on the node. You can specify the className attribute in a few different ways depending on your taste:
Any additional arguments after the first one represent child nodes to be created and appended. These arguments can be DOM elements themselves (e.g. inline $.FOO calls as above), or they can be numbers or strings which are converted to text nodes, or they can be arrays, in which case each element of the array is handled in this same way.
This interface is inspired by Bob Ippolito’s MochiKit DOM API, although it doesn’t implement all of the features of that one (yet).
The code predefines most of the common tags; you can add additional tags by calling:
Or simply add the tag names to the tags list in the code.
One last definition is $.NBSP which defines a non-breaking space (same as in HTML).
$._createNode is an internal helper function used by the $.FOO functions. I would have hidden it away as a nested function, but I wanted to avoid any unnecessary closures.
This code doesn’t actually depend on any of the features of jQuery except for the presence of the $ function—and it uses $ only as a way to avoid cluttering the global namespace. I haven’t tested it with Prototype.js, but it should work equally well there. Or the code can be used with no library, by preceding it with:
Here is the source code, or you can download it:
Coolest satellite ever

JSON for jQuery
Update 2007-09-13: As of version 1.2, the jQuery core now supports cross-domain JSONP downloads as part of the native Ajax support. I suggest you use this support instead of the plugin.
jQuery is a nifty new JavaScript library by John Resig. It features a $() function like the one in Prototype.js, but beefed up with CSS and XPath selectors, and with the ability to chain methods to do interesting things with concise code.
Unlike Prototype, jQuery doesn’t mess around with built-in JavaScript objects. It’s new—too new to have a version number!—but I’ve been writing some code with it and enjoying it.
jQuery provides an easy way to write plugin methods to extend the $ function. For you JSON fans out there, here is a JSON plugin for jQuery which lets you write code like this:
You can of course use an anonymous function if you prefer:
Or, using jQuery’s method chaining, you can combine calls like this code which displays a “Loading…” message when it starts loading the JSON resource:
To install the plugin, simply paste this code into a .js file and load it after loading jquery.js:
This adds a json() method to the $ function. The first argument is the URL to the JSON resource, with the text {callback} wherever the JSON callback method should be provided. In a JSONP URL, you would use jsonp={callback}; in a Yahoo! JSON URL you would use format=json&callback={callback}.
The second argument is the callback function itself. When the JSON resource finishes loading, this function will be called with a single argument, the JSON object itself. Inside the callback function, this is a reference to the HTML element found by the $ function. (If $ found more than one element, the callback function is called for each of them.)
The callback function is required, so this code won’t work with plain JSON APIs like del.icio.us that don’t let you specify a callback function. This would be easy enough to fix; I didn’t need it for the code I was writing, and didn’t think of it until just now. :-)
The code goes to a bit of extra work to create both an array entry and a unique global name for each callback. The global name is what is substituted into the {callback} part of the URL. It uses this name instead of the array reference to ensure compatibility with any JSON APIs that don’t allow special characters in the callback name. In fact, in the current code the callbacks[] array entries are not really used, but I figured it could be handy to have an array of all outstanding callbacks.
Update: John Resig suggested a couple of improvements to the code, so it’s updated, simpler and better now.
Update 2: Code updated to include Stephen and Brent’s fixes from the comments.
Worst Windows security flaw yet (updated)
Update: Microsoft has now released their official patch for the Windows Metafile security flaw. For detailed information, see the ISC report.
(outdated content from 2006-01-03)
In case you don’t already know about it, the new Windows Metafile security flaw is a nasty one. Do not wait for the Microsoft patch due next week. Protect your system now with Ilfak Guilfanov’s unofficial patch. After installing the patch, you can test your system to confirm that the bug is fixed. (Click on the Kevin Gennuso link on that page to open a .wmf file that attempts to start calc.exe. If you get a normal Windows Picture and Fax Viewer window instead of calc.exe, you are good to go.)
After Microsoft’s official patch is released, you can uninstall the unofficial patch.
I didn’t review the code for the unofficial patch, but people who did review it describe how it works in the WMF FAQ. The patch works just the way I would have coded it myself.
The FAQ also recommends unregistering shimgvw.dll in addition to the patch. I don’t think this is necessary, but it wouldn’t hurt.
Blog on Drupal now
We’re up and running with a Drupal version of the blog now. This probably means the RSS feeds will have duplicate entries—and that may happen again as I do some touchup editing to make the old entries display correctly. Sorry about that!
One of the deciding factors was the slick GeSHi syntax highlighter, which I tweaked up a bit to do zebra stripes. Those really help keep code readable when lines wrap in a narrow window. Check out the code samples in this page, and try making the window narrow to see the zebra stripes do their thing. (Alas, they only appear when you go to the site, not in the RSS feed.)
The code syntax highlighting works in comments too. I may change the <geshi> tag; that’s a bit of an experiment to get GeSHi and Markdown to work together.
More about the conversion later, time to call it a night!
WordPress spam fiasco
I’ve been thinking about moving this blog from WordPress to Drupal. I use Drupal for other sites, and with some of the contributed modules it has features that would be handy here.
Last week I ran a test conversion using Sam Revitch’s WordPress-to-Drupal conversion script. Everything carried over to Drupal beautifully, even the custom URL setup, but I noticed there were nearly 2000 comments in Drupal—a lot more than I’d ever seen on the blog or in the WordPress admin pages. I looked in the WordPress database with phpMyAdmin and found the extra comments in there, flagged with comment_approved = spam. Most of those really were spam, but there were a couple dozen legitimate comments that had been mistakenly tagged as spam.
That wouldn’t be so bad if the WordPress admin UI had given me any clue that these false positives (and the actual spam comments) were hiding in the database. But they don’t show up anywhere in the admin pages. The first time I ever noticed them was when the conversion script copied them over. (I suppose that could be considered a bug in the script—should it copy spam-tagged comments? But I’m glad it happened or the comments might have been lost completely.)
So, to the couple dozen people who posted comments and never saw them appear (nor any reply from me or anyone else), my sincere apology. They will show up when I straighten this out.
That would have been a week ago, except that once I saw the blog in Drupal, I asked myself if I was sure I didn’t want to try Typo—mainly because I’ve been itching to do something with Ruby on Rails, and a good way to learn a new language or framework is to start with an existing application and make some changes to it.
So far the results are mixed. Typo is a lot of fun and it has most of what I need in a blog, and coding some of the missing features would be educational. Actually getting to where you can test and deploy a Rails app like Typo is a total pain. With Drupal (or WordPress) I can have a basic site up and running in a few minutes on just about any hosting setup—including XAMPP on any handy Windows PC. Just unpack the tarball, edit the configuration file, create the database, and go to town.
But even on a Rails-friendly host like TextDrive, setting up a Rails app is downright scary, at least if you use Lighttpd like everyone says you should. I can see where there’s a market for a specialized hosting service like RailsAppHosting!
I couldn’t get Typo to run reliably on a Windows machine, so I built a Debian virtual machine and have been running it there. But it freezes many times a day. It won’t load any pages, nothing shows up in the console log. Other apps on the Debian machine respond normally. After a minute or two, Typo wakes up from where it left off. I figured this is probably just something about the virtual machine, maybe the fact I’m running Rails under Webrick or something, but then I saw this thread on TextDrive which has me worried.
I suppose I could just fire up the Drupal site and be done with it, and find some other project to learn Rails with.
Goodbye Adobe
![]() After three and a half years at Adobe, I left the company this summer. Basically, I got fired.
After three and a half years at Adobe, I left the company this summer. Basically, I got fired.
It’s a long story, which I will tell someday. In the meantime, I wanted to apologize to anyone who was looking for the next thrilling installment of the Ajax-style PDF series. As you can guess, my enthusiasm for anything Acrobat has been muted slightly.
But, enough waiting around, I will get back to it and post part 2 soon…
My Scobelized Bogen

Before Robert Scoble was a famous blogger, he worked at a great little camera and appliance store in San Jose called LZ Premiums. I used to stop by the store and annoy Robert because I hardly ever bought anything. (I wasn’t checking out the prices and then going off to the competition to buy, honest! Just enjoyed window shopping.)
Finally, one day I ordered a nice Bogen/Manfrotto 3246 tripod with the 3063 mini fluid head. It’s funny how some things stick in your mind: I remember vividly the smile on Robert’s face when I came in to pick up the tripod and he brought it out for me. At last, I had bought something!
I still have the tripod, and it’s served me well all these years. Besides video, it makes a great platform for a binocular mount. In the photo, my daughter Rachel is using it to view that great sunspot cluster that appeared a year ago. (Yes, those are proper solar filters on the binoculars, and it is perfectly safe to look at the sun through them.)
Why am I posting this today? Robert offered to put people’s blogs on the computers at the PDC, so just in case he actually gets a chance to do mine, this is a little tip of the hat. :-)
Why do large displays have so few pixels?
Engadget loves big LCD monitors, and today they are reporting on the Philips 190PX and 200W6.
At 19” and 20.1” diagonal size, these displays are big, all right, but so are the pixels.
The 200W6 has 1680x1050 pixels, or 99 pixels per inch (measuring horizontally or vertically).
The 190PX has 1280x1024 pixels, or 86 pixels per inch. Those are huge, coarse pixels.
For comparison, my ThinkPad A30p has 1600x1200 pixels on a 15” panel, or 133 pixels per inch. That’s 1.5 times the linear density and 2.4 times the areal density of the 190PX.
Even my old ThinkPad 600 has a higher pixel density than the 190px, with 1024x768 pixels on a 13.3” panel giving 96 pixels per inch.
Why are small pixels better than large ones? The same reason that a 600 dpi (dots per inch) laser printer is better than an old 144 dpi dot matrix printer. If you print text at the same physical size on both printers, the 600 dpi gives you much better print quality than the 144 dpi.
The same is true for displays, if you adjust the text size to be about the same physical size instead of just letting the text get smaller because the pixels are smaller. On the A30p, I run Windows in 120 dpi mode instead of the default 96 dpi. In Windows XP, this setting is hidden away in the Display control panel, Settings tab, Advanced button. (It’s possible to use a custom pixel size so that I could match my 133 pixels per inch resolution, but not all programs work well at custom resolutions, and 120 dpi is close enough.)
By running in this display mode, I get text that is about the same physical size as text on a coarser display in the default 96 dpi mode. But there are many more pixels making up each character, giving much better looking and more readable text—especially with ClearType. Those extra pixels really let ClearType do its job, even to the point where serif text is good looking and readable. Serif text is notorious for being unreadable at small sizes on a computer display, and the problem is simply too few pixels to render the serifs cleanly. With more pixels per character and ClearType, the picture changes completely and even relatively small font sizes look good and are easy to read.
By comparison, when I look at a display like the 190P6, the text is coarse and grainy. Of course, I could run any display in 120 dpi mode, so the text would use the same number of pixels as on my ThinkPad, but 120 dpi mode on an 86 dpi display makes everything huge.
To get the same pixel density as my ThinkPad A30p, a 19” display would need to have about 2000x1500 pixels. Now THAT would be a display. Let me know when somebody makes one!
A silverfish in my keyboard!
Oh man, this is gross. I was reading Lambda the Ultimate on my ThinkPad, with my hands resting on the keyboard’s home row as you normally do when scrolling around with the TrackPoint.
I happened to notice a piece of brown dirt between the spacebar and the TrackPoint buttons. Maybe a crumb that fell on the keyboard or something. I was about to get a toothpick to lift it off the keyboard, when the “dirt” started moving!
It was a silverfish, crawling up from inside the keyboard. Who knows where it had been down there and what it had been eating—or leaving behind. I’m just glad I didn’t squish the thing by typing on it.
I got rid of the ’fish real quick by blowing on it—a quick, explosive puff of air from the side that flung it into the air and… Well, I didn’t see where the silverfish landed. At least it wasn’t in my glass of wine.
Ajax-style PDF part 1: fading highlight setup
If you haven’t already seen it, take a look at Adobe’s walking talking PDF tour of Acrobat 7.0. It’s one of the most creative PDF files I’ve ever seen. (Don’t stop after the first few pages; there are some funny bits near the end.)

Obviously, a lot of work went into making this PDF, but the technical side of it is actually pretty simple. We can add some scripting magic to make it even better.
Take page 11, where our narrator explains the links he’s standing next to, pointing to each one as he describes it:

The links just sit there when he points at them. It would look good, and be a nice usability touch, if we could apply an Ajax-style fading highlight to each link as he points to it:

First we need to find out how the existing page works. If you have Acrobat Professional, you can see it by using the Select Object tool on the Advanced Editing toolbar. That’s a Flash movie on the right with the narrator in it. Right click it and open its Properties to see the Page Enter event and a .swf rendition (Acrobat’s term for a media clip and its associated settings):
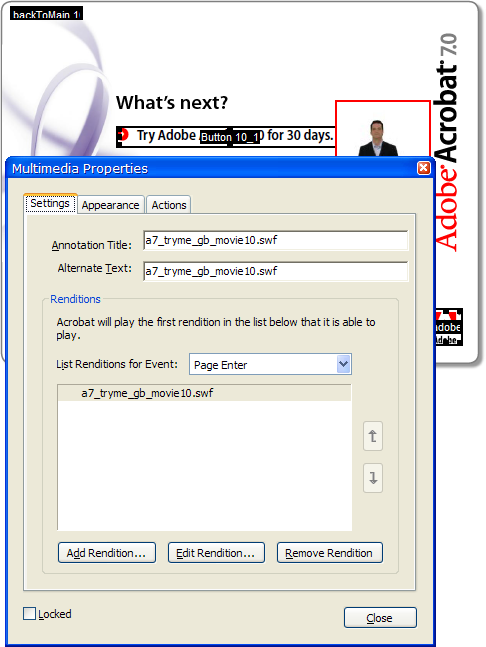
Each page is like this, with a Flash movie embedded in the page that runs on the Page Enter event.
The links on the left are (no surprise) PDF pushbutton form fields.
With our narrator in a Flash movie and the links being PDF buttons, is there a way to connect the two? We can write some JavaScript code in the PDF to fade a highlight on and off for a link, but how do we trigger that code at the right time as the movie plays?
Well, one thing at a time. It would be fun to just see the fading highlight in action, so we’ll write that bit of code first and hook it up to a temporary button to test it. The code will use doc.getField(name) to get a JavaScript Field object, and then it can set the field’s fillColor property to change its background color. If we do that on a repeating fast timer we’ll have the fading highlight effect.
For a quick test before we write any code, we can right click one of the buttons and open its Properties to change its fill color manually:
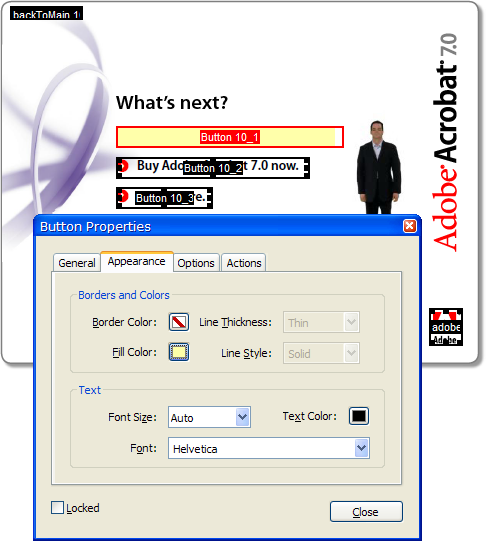
Oops. That worked, but it didn’t do what we want. We got the fill color but the icon and text went away. Let’s Undo it and try something else. (And note that the fill color doesn’t extend all the way to the right end of the field. That’s because the Flash movie overlaps the field. Hopefully this won’t cause any problem.)
We can create a separate field that is a solid rectangle, and if we get the Z-order right it should do what we want. A text field with no text in it will do the trick. Let’s try it without worrying about the exact layout first:
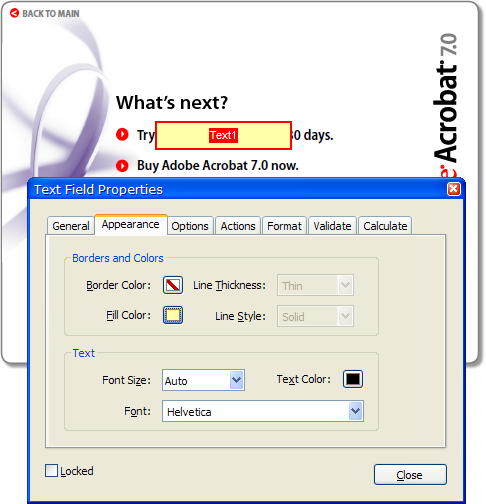
I guess that’s some kind of progress. Maybe changing the Z-order will fix it. The tool to change that is tucked away in Acrobat’s Advanced/Forms/Fields/Set Tab Order menu command:

Now we can click on the fields in order to set their tab order (which is also their Z-order), and if we put the text field in the tab order before the button, we get the transparent background highlight we were looking for:

Finally, we move and resize the text field and we have our field highlight, at least in static form. Here’s the page after a Select All (Ctrl+A) to show all the field rectangles:
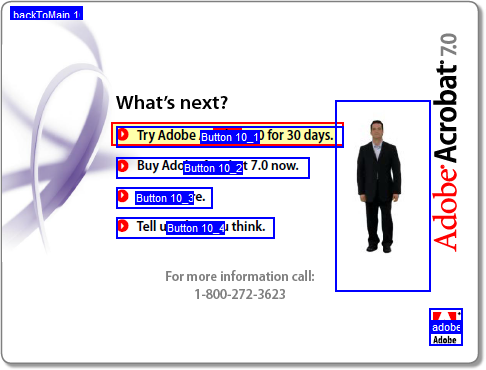
Creating a separate text field for the highlight was a minor nuisance, but does have one benefit: we were able to fine tune the highlight position relative to the button icon and text:

The blue outline is the pushbutton field that we tried to work with originally. As you can see, the pushbutton field rectangle doesn’t have consistent margins around the icon and text (and no margin on the left). With a separate text field—the red outline—we can adjust it so the highlight is positioned nicely:
Now that we have a highlighter field, we should be able to write some code to control it. While I was editing the field I changed its name from the default Text1 to Hilite, so we should be able to use getField and set its fillColor. Let’s try it in the JavaScript console first:
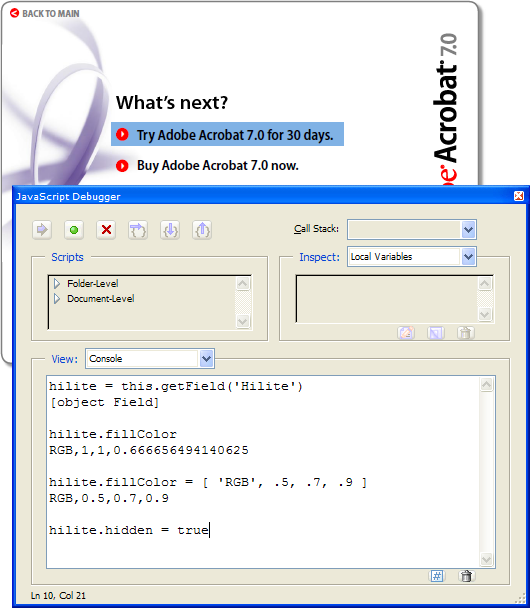
Looks good! We got a reference to the field in the hilite variable and looked at its current fillColor property. Then we changed the fillColor and the visible field changed as expected.
The last statement in the JavaScript console (not yet executed in the screen shot) hides the field, so we can save the file and it looks normal. It doesn’t matter that we left the field the wrong color; we’ll take care of that in the code that makes it visible again. For now, it’s time to save the file and take a break. In the next installment we’ll write some code to create the fading highlight effect.
p.s. Here’s an Acrobat editing tip: Open the General tab of Acrobat’s Preferences dialog and turn on the single-key accelerators. Then you can use the H key for “hand” (normal) mode in Acrobat, R for the object selector, and so on. Hover the mouse over a toolbar button to see its shortcut key. It makes this kind of editing a lot easier where you switch tools so often.
Disclaimer: I work for Adobe, but this is my own summer vacation project, not any kind of offical Adobe code.
Why I love the TrackPoint
 Ten years ago, when Windows 95 first supported multiple pointing devices, I tried an experiment: I set up three different pointing devices so I could switch back and forth among them and see which I liked. I already had a mouse, of course, so I bought a new IBM keyboard with a TrackPoint built into it, and a touchpad which I placed below the space bar.
Ten years ago, when Windows 95 first supported multiple pointing devices, I tried an experiment: I set up three different pointing devices so I could switch back and forth among them and see which I liked. I already had a mouse, of course, so I bought a new IBM keyboard with a TrackPoint built into it, and a touchpad which I placed below the space bar.
 Essentially I had the same layout as IBM’s more recent UltraNav, plus a mouse.
Essentially I had the same layout as IBM’s more recent UltraNav, plus a mouse.
At first, the TrackPoint felt a bit odd and hard to control, while the touchpad was easy to get used to. But after spending the money on that keyboard, I made myself use the TrackPoint for a few days… and then it clicked.
Once I got used to it, the TrackPoint became so natural that I wasn’t aware of using it. If I wanted the mouse pointer to go somewhere on the screen, it would just go there. I didn’t think about taking my hand off the keyboard, reaching over for the mouse, and then moving it. The mouse pointer would just go, seemingly because I willed it.
I was visiting a friend some time later and sat down to use their computer, and I started getting flustered because the mouse pointer wasn’t moving where I wanted it. In fact, it wasn’t moving at all, and I couldn’t figure out why. Why wouldn’t it just go like it usually did?
Then I looked down and saw my index finger moving around, trying to push on a TrackPoint that wasn’t there.
Because the TrackPoint is available in the touch typist’s home row position, it removes the barrier between pointing and typing. Consider how you operate a context menu: You can right-click with the mouse, move the mouse to the desired menu item, and click it. Or if you’re a real geek, you may know that you can type Shift+F10 to open the context menu, then press a shortcut letter or the cursor keys and Enter.
What you’re unlikely to do is combine these two modes of operation. You probably won’t right-click and then type a shortcut letter even though that can be very convenient. But with a TrackPoint, mixing the keyboard and mouse are perfectly natural. I often right-click and then type a shortcut letter, or mix up the mouse and keyboard in other ways. I’m never in “typing mode” or “pointing mode” like I would be with a mouse or touchpad.
If the TrackPoint is such hot stuff, why isn’t it more popular? You’ve got IBM/Lenovo, Motion Computing, sometimes Toshiba and Dell, and who else? Every other notebook has a touchpad.
I think one reason is that first impression. A touchpad makes a better first impression than a TrackPoint–especially at a retail store where the TrackPoint cap is likely to be damaged or missing. The benefits of the TrackPoint don’t become apparent until you’ve had some time to get used to it.
It’s a shame, because for someone like me who points and types, points and types, points and types, there’s nothing like a TrackPoint.
Netflix freakout
Netflix has been freaking me out lately.
At lunch couple of weeks ago, a friend of mine recommended the Alfred Hitchcock classic Dial M for Murder. That night I logged into Netflix, and as usual, they told me You Have Recommendations! And right there at the top of the page was Dial M for Murder.
I thought that was a pretty good coincidence, but tonight I was reading Engadget’s article on the Robot Gunslinger from Westworld. I saw that movie years ago and thought I would check it out again. So over to Netflix, where of course You Have Recommendations!
No, it wasn’t Westworld. My top recommendation was The Magnificent Seven. And just before visiting Netflix, I’d read this line in the Engadget article about Westworld:
“Yul Brynner plays a robotic reproduction of Yul Brynner playing Chris from the Magnificent Seven.”
I think Netflix has hired someone to spy on my lunches and blog reading. There is no other possible explanation.
FriendsLight theme updated for Drupal 4.6
The previous version of the FriendsLight theme works with Drupal 4.5.2 but not with Drupal 4.6.0. Here’s an updated version for 4.6.0 (only—use the previous version for 4.5.2).
See this discussion for information about the code change in this version.
Update 1: There were several bugs in the previous version. It basically was not usable at all on 4.6. I merged in the code changes from the friendselectric theme to fix the problems with 4.6. The link above is to the fixed version. Sorry about that!
Update 2: The new version attached to this post fixes the ?q= bug noted in the comments.
Uncool ripple effect in Mac OS X Tiger Dashboard
Mike Sax reports on the new Dashboard feature in Mac OS X Tiger.
Two things struck me watching the demo movie:
Flipping the widgets over to enter settings on the “back” of them is a great idea. It ties together the settings panel and the normal display panel very nicely. OTOH, it wouldn’t help in a case where you’d like to see the effect of your settings immediately. What do you do then: Keep flipping the widget over back and forth until you have it the way you want?
When you drop a widget on the dashboard, it appears with a “cool ripple effect” (Apple’s words). To me, this was interesting the first time, annoying the second, and by the third time I was hoping I would never have to see that “cool ripple effect” again.
Why would a dashboard ripple anyway? Am I supposed to believe it’s a body of water? Maybe it wouldn’t be so annoying if it made the slightest bit of sense.
Lions in our trees
My little neighborhood made the news. An 80 pound mountain lion was shot down from a tree, three blocks from my home, on a street that I frequently take walks on.
Network follies
I have lost all faith in my own intelligence.
I’d brought my ThinkPad over to my manager’s office to demo some network code I was working on. I had a couple of virtual machines running on the NAT network, so they could see other machines on the LAN as well as the host and each other. I unplugged the network cable, took the machine a few doors down, turned on the wireless network, and showed off my new code. Or tried to anyway. One little problem: The VMs couldn’t see the rest of our network through the wireless link. The host ThinkPad could ping other machines via the wireless, but the VMs couldn’t.
I’m pretty sure I’ve switched between wired and wireless connections using VMs with NAT before and it’s worked OK, or maybe I’m imagining it. In any case, it wasn’t working today. I fiddled with a few things, even tried rebooting the VMs, but never got it to work. The two VMs could see each other with no problem, so I just ran the demo that way. It was all I really needed anyway–virtual machines are great for demoing network software without having to carry a network around. But it would have been fun to show the connection to the rest of the LAN as well.
It wasn’t until hours later that I realized how easy it would have been to solve the problem: we could have simply taken twenty seconds to walk back to my office! We didn’t have an extra network connection handy in my manager’s office, but obviously I had the one I’d just unplugged. There was no particular reason we had to do the demo in one place or the other.
You’ve never done anything like this, have you?
FriendsLight theme with styled preview
If you’re like me, you’ve lost your work in Drupal a few times when you’ve previewed an edit and then forgotten to save it. Drupal’s preview page hardly looks any different from a normal display page.
When my boss lost his work because of this preview page confusion, I figured I’d better do something about it, so I updated the FriendsLight theme to highlight preview pages visually. I posted some screen shots on my blog. Or, you can try the new theme out by entering a comment to this post and previewing it.
Unfortunately, Drupal does not provide any information to its themes to tell them they are rendering a preview and not a fully saved message. Fixing this requires changing the Drupal core modules node.module and comment.module, but it’s a straightforward one-line change in each. The code simply adds $node->preview and $comment->preview flags which can be tested in a theme or theme engine.
Favicon gallery with commentary
I never thought favicons would be fun until I saw Michael Pierce’s Favicon Gallery. At first it just looks like a page with hundreds of favicons, but move the mouse around over the icons and watch what happens. Quite a nice piece of work!
TextBar Drupal module for Markdown and Textile
Here’s a treat for Drupal users who support the Markdown and Textile input formats on their sites. The TextBar module adds a formatting toolbar for these input formats to Drupal’s content and comment texarea fields.
To try out the TextBar right now, you can comment on this message. (You don’t need to save your comment unless you want to :-) but you’ll be able to try out the toolbar while editing it.)
You can try it with both the Markdown and Textile input formats (and if you select the Filtered HTML format the toolbar will disappear). The Textile input filter is not actually installed on this site, though, because of a conflict between the Markdown and Textile modules. So you won’t be able to actually post a comment in Textile, but you can see how the TextBar generates Textile codes.
New version of FriendsLight
I turned off the page border completely. I think it looks a lot better this way. Also turned off the underline for hover, and replaced the gradient fill in the heading with a solid color. The gradient fill probably looks great on a CRT, but on my ThinkPad it is streaky and distracting.
Will revisit the other issues later.
Here’s the new version. Enjoy!
New Drupal themes
Steven Wittens has put together a nifty new Drupal theme called FriendsElectric. Here’s a discussion about the theme and a live demo.
Inspired by Steven’s efforts, I made a few little changes to his theme and called it FriendsLight. It’s a work in progress, but I like it better than the other Drupal themes I’ve tried.
Drupal is my (current) favorite content management system for building community websites. I keep trying other CMSes but keep coming back to Drupal.
Bugs
There are always bugs, aren’t there? I noticed that my code to remove the right sidebar for admin and editing pages only works if you use clean URLs. I’ll fix it to work with either kind of URL. Also, the footer text seems too big and bold. Anything else I should fix while I’m at it?
FriendsLight Drupal theme
Here is what I changed in FriendsElectric to arrive at FriendsLight:
- Removed all the negative character spacing to make the text easier to read.
- Replaced the graphic margins with a smaller white margin all the way around.
- Moved the footer text into the main column instead of below the left sidebar.
- Made the footer text larger and bold.
- Changed some of the link colors to make them less lipsticky.
- Added a light gray background color when hovering on most links.
- Removed the bullets on the “by Author” and “Author’s blog” lines in each post.
- Moved the “by Author” line up to the top of the post, below the title.
- Fixed a bug where short page content caused the sidebar shading to be lost.
- Lightened the text color of the primary and secondary links.
- Added code to remove the right sidebar on all admin and content creation/editing pages.
If you like these changes, thank Steven Witten for making a theme that is so easy to change. If you don’t like them, blame me. :-)
Vonage, Si! WRT54GP2, No!
We got Vonage phone service at home a few weeks ago, and it has been just great. For $27.24/month total cost, we get unlimited calls to the US and Canada, with caller ID, voicemail, and all of the custom calling features the phone company offers and then some. I especially like the simultaneous call forwarding, where incoming calls ring both the Vonage line and another number (such as a cellphone) at the same time, and I can pick up the call on either one. The service works with our existing phones, and we are porting our old landline phone number to Vonage.
I found out about Vonage while shopping for a router at Circuit City. (Don’t laugh, it’s the closest store with a decent selection of computer stuff.) I was going to get another Linksys WRT54G, but then I saw they had the WRT54GP2 combo router and phone interface, so I got that instead. I figured with the router and phone interface combined, I wouldn’t have to worry about any quality of service (QoS) issues.
Big mistake. The first WRT54GP2 wouldn’t work at all. I spent an hour on the phone with Vonage tech support with no success. The replacement worked fine, but there was a problem in the sound quality that I couldn’t stand: a constant background noise similar to the sound a 56K modem makes after it’s connected. I thought, “This is what Vonage sounds like? It stinks!”
I got back on the phone with Vonage hoping they could do something about this, but the problem wasn’t with their network, it was noise being generated inside the unit itself. Even with nothing plugged into the WRT54GP2 but a phone and power, I could hear the noise. Reviewers on Amazon and elsewhere have noted the same problem.
So back this went and I got a regular WRT54G router and a separate PAP2 phone interface. The WRT54G connects to the cable modem as usual, and the PAP2 sits behind it on the LAN side. I updated the WRT54G to the latest firmware, which does support QoS, so I could give priority to the port the PAP2 is plugged into, and we were off and running with fine sound quality and hardly any background noise.
Subdivide your Netflix account
Netflix has a new feature in the works. You will be able to subdivide your account into “profiles” with their own queues and mailing addresses. If you have the typical 3-at-a-time Netflix program (meaning you can have three discs checked out at once), you could split it into three different profiles, each one effectively on a 1-at-a-time program. Or you could have one profile with 2-at-a-time and a second profile with 1-at-a-time.
I got an unintentional sneak preview of this feature when I went to the Change Shipping Address page on Netflix today. It looks like the Related Questions section on this page was accidentally linked to information about the profile feature instead of information about changing your address. In this section is a link to an Assign DVDs page, where you are supposed to be able to split up your queue to your different profiles, but the link doesn’t work.
If Netflix actually does roll this feature out, it will be very cool. But they may want to change the name: They already have something called a “profile” that is completely different (it’s a page where you can publish your reviews and comments).
Update: Account profiles are now available. If you go to your Netflix account you can create them. Here is more information about profiles.
You can also filter the Netflix site by movie rating for each profile. I’m going to use this to create a separate profile for our kids to log in and see only the family and kid-friendly movies.
100,000
And a million without their homes. Our prayers, and our tears, go out to everyone affected by this disaster.
Wikipedia coverage: 2004 Indian Ocean earthquake Affected countries USGS animation More Wikimedia
{kind=link}
{kind=link}
Cyberguys does it again
Where does Cyberguys find all these things? This month they have singing magnets (toss them in the air and they sing):


A USB aquarium:

And a USB snowman:

Oh, they have all kinds of practical things too.
(Updated 1/17/2005 to fix broken links)
Basic Firefox tweaks

Mozilla Firefox is a mighty fine browser right out of the box. If you haven’t tried it out yet, I highly recommend it.
Firefox is also highly customizable. Here are some basic tweaks that make Firefox even better.
Fonts
The first thing I do when I install Firefox is open the Tools/Options dialog and adjust a few of the settings there. On the General page, I click the Fonts & Colors button and choose better fonts. By default, Firefox uses the mediocre Times New Roman and Arial fonts. Georgia and Verdana are much more readable choices for the Serif and Sans-serif fonts.
I also change both of the Size (pixels) settings to 18, and the Minimum font size to 14. Finally, I change the Display resolution to 120 dpi to match my Windows setting.
Here are my font settings:
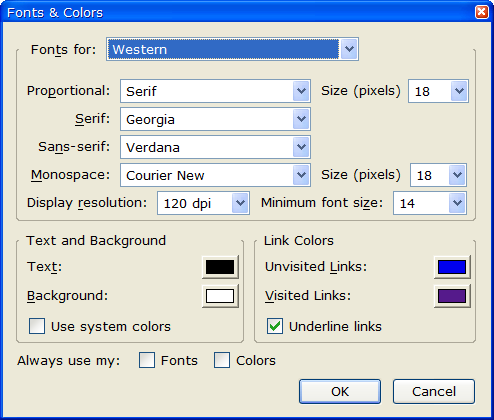
These are tuned to look good on the high-density 1600 x 1200 15” display on my ThinkPad. On a lower-density display you may prefer other settings, but in any case you’ll find it worthwhile to spend some time in this dialog.
The Display resolution setting has an unusual user interface. You don’t specify the resolution directly; instead you select Other… in the dropdown combo box, and then another dialog pops up with a line you’re supposed to measure. That’s nifty, but I just wanted to set it to 120 dpi, so I tried various values in the dialog until I found that 6.35 centimeters was the magic number.
Downloads
By default, Firefox saves all downloaded files on your desktop. I keep a Downloads folder with subfolders for the various programs and files I download. So back in the Options dialog’s Downloads page, I set it to Ask me where to save every file.
Tabbed Browsing
In the Advanced page of the Options dialog, I change the Open links from other applications in setting to a new window. The default setting is the most recent tab/window, which I don’t like at all. When I click a link in some other application such as my email client, I don’t want it to replace a website that I had already open, I want a new window.
Firefox’s tabbed browsing is wonderful, BTW. I use it to group related sites together in a single window. For example, I often investigate several topics in parallel. Typically I start by opening a new Firefox window and doing a Google search. Then I hold down the Ctrl key and click on various links from the search results. These pages all open as tabs in that same window.
Then I may have some other topic to research, so I open another new window and repeat the same procedure. So each window contains a set of related search results. It’s a great way to organize related pages, and you can save the entire set of tabs in a window together in a bookmark folder to re-open them as a group later.
Extensions
Firefox has hundreds of extensions available from the official site and the unofficial Texturizer site. I like to keep my Firefox lean and fast, so I only use a few of them. Here’s my basic set:
Alas, there are still some websites that are hard coded to work only with Internet Explorer, and IE View makes it convenient to get to those sites.
I like the way IE duplicates a window’s current state when you use Ctrl+N to open a new window. Firefox by default opens your home page in a new window when you use Ctrl+N, and if you use Ctrl+T to open a new tab, the new tab is blank.
I like IE’s window cloning, so the Clone Window extension fixes this. I set its Options to New Window command should open: Cloned Window and New Tab command should open: Cloned Tab.
Clone Window isn’t listed on the official Firefox update site, so when you click the installation link it you’ll get a warning at the top of the Firefox window that www.pikey.me.uk is trying to install software on your computer. Click the Edit Options button which will open the Allowed Sites dialog, then click Allow and OK. Finally, click the installation link again to install the Clone Window extension.
Firefox includes a basic Google search (along with several other searches) in its standard toolbar, but it doesn’t have all of the features of the Google toolbar for IE. The Googlebar brings these goodies to Firefox. One thing it doesn’t have is PageRank, but there are a number of variations of the Googlebar that include PageRank.
Like Clone Window, Googlebar isn’t listed on the official Firefox update site yet. The installer is located here (or via the link above). Follow the same procedure described for Clone Window to install it.
There are a lot more extensions than that. Every time I look at one of the Firefox extension sites I see something else I’m tempted to try, such as the nifty Wayback extension which gives you easy access to historical versions of sites from the Internet Archive’s Wayback Machine.
Keyboard shortcuts
You probably know that Internet Explorer lets you go to a .com site without typing the www. and .com; just enter the domain name without those and hit Ctrl+Enter. Firefox does that too, and it also lets you use Shift+Enter for a .net site and Ctrl+Shift+Enter for a .org site. So, you can type “archive” in the address bar, hit Ctrl+Shift+Enter, and you’re at the Internet Archive.
You can increase the text size of any site (any site) with Ctrl+Plus (you don’t need the Shift key, so I suppose it’s really Ctrl+=, but it’s easier to remember it as Ctrl+Plus), and decrease the text size with Ctrl+Minus.
Ctrl+B opens the handy Bookmarks sidebar. Even if you like to use the Bookmarks menu to access your bookmarks, the sidebar is a great for creating them. To the left of the site address (URL) in the address bar there is an icon for the website you’re viewing. Drag that into the Bookmarks sidebar wherever you want it. (If there’s no icon, the blank spot to the left of https: will work as an icon anyway.)
The rest of the keyboard shortcuts are listed in the Firefox help.
Sorting your bookmarks
Firefox displays its bookmarks in some peculiar order by default. You can easily sort them by name, though.
For the Bookmarks menu, open the menu and right-click on any of the bookmarks, then select Sort by Name.
You can sort the Bookmarks sidebar (Ctrl+B) by opening the separate Bookmarks Manager using Bookmarks/Manage Bookmarks. On the View menu are several sort options which apply to the Bookmarks sidebar as well as the Bookmarks Manager.
Advanced tweaks
Fans of Reason Magazine’s lively Hit & Run blog may have noticed that the text on this blog comes out really tiny in Firefox, because of some unfortunate font choices in in the style sheets used on this site. This is likely to improve now that some of the Reason staffers have switched to Firefox.
But there’s no need to wait for Reason to fix their site. The font settings I listed above will fix most of the problems at Hit & Run. The one remaining problem is that the type used for comment text is still too small. It’s easy enough to fix this with Ctrl+Plus, but a better fix is to override Reason’s style sheet. If you don’t mind a bit of text editing, this is easy to do.
First, you need to find the “profile” folder for Firefox. On a Windows 2000 or XP system, this is located in:
C:\Documents and Settings\your name\Application Data\Mozilla\Firefox\Profiles
That’s a hidden folder, so you’ll need to use Tools/Options on the Windows Explorer folder window and go to the View tab, then turn on the Show hidden files and folders option.
On a Windows 98 or Windows Me system, the Firefox profile is likely to be in:
C:\Windows\Application Data\Mozilla\Firefox\Profiles
That location may be different if you’ve enabled multi-user settings in the Users control panel. If you don’t find it, use Start/Find/Files or Folders to search for the Firefox folder.
Inside the Mozilla\Firefox\Profiles folder on your system, you’ll see a folder with a name like
v7qf3bzn.default. This is your actual Firefox profile folder. Firefox uses randomized names like this to help protect your profile against intruders.
Inside that folder is a folder called chrome. This is where you can do some interesting customization. In a fresh Firefox installation, there are two files here with a few examples of what you can do. userChrome-example.css is for customizing the “chrome”, things like the menu bar, toolbars, and such. userContent-example.css is about the content of a web page, and it’s the one we’re interested in here.
Copy userContent-example.css to userContent.css and then edit that new file. Add this text to the end and save the file:
Now close all Firefox browser windows, re-open Firefox and visit Hit & Run again. The comment text will display in the more readable Georgia font at a decent size, instead of the small Times font it uses by default.
One limitation here is that changes in userChrome.css apply to all sites that happen to use the same style tag, so this may affect other sites besides the one you want to customize. But it can still be very useful for sites like this.
Update: added installation information for Clone Window and Googlebar, and bookmark sorting information.
The Firefox vote
Looking at political party websites in Firefox tells me a little something about each party. (Click images for full size versions.)
The Republicans may be able to pack two grammatical errors into one sentence (“In 2000, less than 17,194 votes decided five states, and 55 Electoral College votes.”), but they have a big tent and Firefox visitors are welcome:

Popups? We don’t need no steenkin’ popups. And the scrolling banner at the top is awfully annoying, but it offers an interesting optical illusion: Stare at the live GOP site for 30 seconds or so, and then look at the screen shot of the same site. Your eyes will tell you that the screen shot has a scrolling banner too, moving the opposite direction.
The Libertarians may have a very small tent, but it’s a friendly one:
No problems with Firefox here, and no scrolling banner to play tricks on your eyes.
How about the Democrats?

Well! We are not using an approved browser, are we? Firefox users are not welcome here. You will use IE or you will use nothing.
Does it get better if we scroll down the page?

Oh. That’s easy to read, isn’t it?
One of the reasons I switched to Firefox is that I can override the font size of any website by simply using the Ctrl+Plus and Ctrl+Minus keys. What about the folks who are still using IE? Can they change the font size of a website? IE does have a Text Size button, but it only works for sites that are gracious enough to avoid absolute font sizes.
What if an IE user needs really big text because of poor vision? Do these sites allow it? Let’s take a look at each one in IE with the Text Size cranked all the way up. (No large versions this time, since the point is to show how the sites might look to someone who can’t see well.)
Republicans:
Democrats:
It is nice to see that the Democratic Party actually does have a website (as long as you’re using their approved browser). And why should you be able to choose your own font size, anyway? The Democrats, just like the Republicans, have already picked out the font that they know is best for you.
Libertarians:
True to their philosophy, the Libertarian Party is the only one that lets you pick your own font size instead of being stuck with theirs.
(Where’s Ralph? Sorry, I got too tired to make that many screen shots. Summary: He’s Firefox-friendly, but just like the Demos and Repos, he knows what font size is best.)
Daylight Saving Tax
How many clocks did you have to change today? This year I’m pretty lucky. I only had to change 19.
Of course, I’ll probably find a few more in the next few days.
Here’s the list so far, for our family of four:
- Oven
- Microwave
- Answering machine
- Two wall clocks
- Four cameras
- Sony reverb (yes, it has a clock)
- Two thermostats
- Three alarm clocks
- Fax machine
- Sprinkler system
- Two cars
Some years have been worse. I recall changing 28 clocks about ten years ago. That was before my computers adjusted themselves for daylight time. For a while that made things even worse, though: I was dual booting Windows 95 and NT, and when the time changed, both OSes decided to adjust the time for me. So I was an hour off in the wrong direction.
Now I do all my software testing in VMware virtual machines, and I’ve given up on putting those on daylight time. I let them run on standard time all year around, otherwise it gets too annoying. Revert to a snapshot and it will want to adjust the time all over again.
I do have one atomic clock that set itself back to standard time automatically. But my daughters have atomic clocks that didn’t, and I don’t see any way to change them unless I turn off the radio synchronization and set them manually. Must research this.
I can’t wait for spring, when we do it all over again, and probably get to church an hour late.
Whose idea was this? Democrats? Republicans? A pox on both their houses. The Libertarians would never pull a stunt like this.
Update: Roy Green informs me that it was not the Democrats, not the Republicans, and not even the Libertarians, but my hero Benjamin Franklin!
Installing OpenOffice (sigh)
“Hey Mike, we just got a new HP computer from Fry’s. They said it was ‘fully loaded,’ but it doesn’t seem to have Word and Excel on it. My daughter needs those to write her term papers and stuff. I don’t know why they aren’t there. Can you put them on the computer for us? I guess that’s kind of like piracy or something, I don’t know much about that. Can you help us out?”
“Sure, Mary, I can help you out. No, I can’t put Microsoft Office on your computer. But have you ever heard of Open Source software? It’s completely free and legal to give away copies. There’s a great program called OpenOffice that should do everything you need. I’ll burn a CD for you [Mary just has a dial-up connection] and bring it to church tomorrow. Then give me a call when you’re home later and I’ll talk you through installing it. Don’t just run the Setup program without talking to me first. Since you’re running Windows XP, there are a couple of little things you need to do specially when you install it.”
Couple of little things indeed. I almost wish I’d given her that pirated copy of Office she wanted. Then I could have just said, “Take the CD home and put it in your CD drive. It will install automatically. Have fun!”
Instead, we spent close to an hour on the phone.
You see, you don’t just install OpenOffice, not if you have multiple user accounts on your XP system like Mary and her daughters do. The normal OpenOffice install doesn’t know beans about multiple users. Instead, you have to first unpack the downloaded setup program (I did that ahead of time and put the unpacked version on the CD). Then you do a “network install” from the command line by running the Setup program in the unpacked directory with a /net option.
Finally, you log into each user account and hunt down another Setup program, this one located in the Program Files directory where OpenOffice was installed. This second Setup is where you enter your name and initials and other information, like what happens automatically with Microsoft Office. It also asks you a really confusing question about Workstation vs. Local installation, but luckily the default is OK.
All of this is after you’ve installed Java. (I did plan ahead and put the JRE on Mary’s CD.)
Now, Mary is a smart lady, but she’s not a technogeek, and she’d never even heard of a command line. I’d love to get all my friends set up with OpenOffice, but I don’t want to spend an hour on the phone every time. If OpenOffice is for normal people and not just geeks, it needs a setup program that works smoothly for a multiuser Windows installation, a single setup with no command lines and no special switches.
(Yeah, yeah, I know. It’s Open Source, so instead of complaining I should submit a patch…)
Acrobat, won't you please, please help me?
Adobe Acrobat has a feature where you can put a PDF file on your website and invite other Acrobat users to mark it up with comments directly on the Web. I was working my way through setting this up, when Acrobat asked me:
Uh, sure, no problem, click OK and the message box is closed. Let’s go find that Reviewing dialog and open its Online Commenting Settings. Hmm… Now which menu is that on? I don’t see it anywhere.
Oh, that’s right, they meant the Preferences dialog. Reviewing panel. Got it.
I don’t see a Reviewing panel? Oh! It was the Online Repository panel of the Preferences dialog, that was it! Hmm… Not there either. Where is this panel I’m supposed to fix?
Um, what was I trying to do in the first place? I forgot!
Confession time: I work at Adobe, on the Acrobat team, so this dialog is as much my fault as anyone’s. No, I didn’t write this particular piece of code, but I didn’t fix it either.
And it may not that easy to fix. If you develop software, especially if you work on large programs that have been around a while, you know how it is.
Does your software do this? I bet we’re not the only ones.
Computers are really, really good at following directions. I’m not. If a program can give me a four-step procedure to follow, why can’t it just do it itself?
Task Manager "tiny footprint" mode
A few months ago, Raymond Chen wrote about an obscure “feature” in Windows that makes Task Manager’s titlebar, menus, and tabs disappear, with no apparent way to ever get them back. This is called Tiny Footprint mode, and Raymond described it as
… one of those geek features that has created more problems than it solved. Sure, the geeks get their cute little CPU meter in the corner, but for each geek that does this, there are thousands of normal users who accidentally go into Tiny mode and can’t figure out how to get back.
The fortunate may find Microsoft’s Knowledge Base Article describing this mode and how to get out of it. Others are not so fortunate. One of Raymond’s commenters spent three days running antivirus software trying to find the problem. Another gave up and reinstalled Windows from scratch!
Well, after seeing all those complaints, I stayed far away from Tiny Footprint mode and didn’t give it a second thought.
Until one day, when I was working on a bug and I wanted to watch Acrobat’s memory allocation and GDI and USER handles. I was getting really annoyed with how much screen space the Task Manager was taking up. It’s odd that Task Manager has such a large minimum window size.
Then I remembered Raymond’s article and gave it a shot. I double-clicked in the whitespace in Task Manager’s window, and not only did the title and menu bars go away (which I didn’t care about one way or the other), but I could resize the window as small as I wanted!
Now I use this mode all the time. Task Manager is a lot more useful when it can target just the information I want instead of taking up a big chunk of my screen.
It is unfortunate that there’s no easily discoverable way to get back out of this mode, but once you know that it just takes a double-click, there’s no real problem at all.
A cupholder for your computer
I’ve never bought anything from Cyberguys, but the catalogs they keep sending me are so entertaining I’ll have to.
My favorite item in their new catalog is this combination cigarette lighter and cupholder that fits in a 5.25 inch drive bay:

Take the soda can out before you eject that CD!
Smoke getting on your display? No problem, use one of these stuffed animals with microfiber tummies:

For your car, here’s an MP3 player with a USB socket on one end and a cigarette lighter plug on the other:

Plug a USB flash drive with your music into the MP3 player, the player into your car’s cigarette lighter outlet, and you’re on the air (literally—it broadcasts to your car’s FM radio).
That USB drive in the picture comes from this Swiss Army knife:

And here’s the niftiest little flashlight I’ve seen:

Cyberguys has a bunch of more practical geek stuff too, but I get a kick out of these oddball items they manage to find.
(Updated 1/17/2005 to fix broken links)
Exploding capacitors and Radio Moscow
Robert Scoble reminisces about listening to BBC on the shortwave, and plugging capacitors into the AC outlet to make them explode.
My capacitor trick was to take a big fat electrolytic and charge it up to 12 volts or so. Then I’d find an audience, and I would grab one terminal of the capacitor in each hand and pretend I was being electrocuted. After a great struggle I’d break free, then take a screwdriver and short out the terminals. Bam! Now that’s a spark!
{kind=link}
Of course, this depended on my friends not knowing the difference between voltage (12 volts, no way it can hurt you) and current (virtually none through the high resistance of my skin, but plenty through the near-zero resistance of the screwdriver).
I discovered shortwave radio when I was about ten, traveling through Idaho with my mom and sister. I found a funny old radio in the motel room and tuned around, finding all kinds of radio stations I’d never heard of before.
“Mom! It’s Radio Moscow!”
“Sure, Mike, we’re in Idaho. That’s Moscow, Idaho.”
It really was Radio Moscow (USSR), but I don’t think she ever believed it.
Use FILE_SHARE_DELETE in your shell extension
A Windows shell extension that provides information from the contents of a file has to open the file to do it. Opening a file locks it to some extent or another, depending on the file sharing flags you use. Even if you open the file for only a moment, that can be long enough to interfere with another program's use of the file.
What happens when someone drags a file from one folder to another, and you have a shell extension that renders thumbnails for the selected file type? Windows calls your IExtractImage interface and you start rendering the thumbnail. Then as soon as your customer releases the mouse, Windows tries to move the file to the new folder. If they move fast enough, this can happen while you've still got the file open to render the thumbnail. That results in this lovely message:
If they're lucky, they'll try again and go a little slower, and it will work! You've finished rendering the thumbnail, closed the file, and Windows can move it with no problem.
There's an easy way to fix this for Windows NT, 2000, and XP. In the CreateFile() call that opens the file, use FILE_SHARE_READ | FILE_SHARE_DELETE in the dwShareMode parameter.
The MSDN documentation doesn't make it clear at all, but FILE_SHARE_DELETE works with MoveFile() in the same way it does with DeleteFile(). In other words, it gives you Unix-style delete/rename semantics. Even while you have the file open, Windows can delete it or rename it right out from under you, but you can keep reading it—your handle to the file remains valid until you close it.
So, in the case above, Windows moves the file to the destination folder without interference from your thumbnail code.
Mike Mascari ran a test of this and posted the results in the comp.databases.postgresql.hackers newsgroup:
Well, here's the test:
foo.txt contains "This is FOO!"
bar.txt contains "This is BAR!"Process 1 opens foo.txt
Process 2 opens foo.txt
Process 1 sleeps 7.5 seconds
Process 2 sleeps 15 seconds
Process 1 uses MoveFile() to rename "foo.txt" to "foo2.txt"
Process 1 uses MoveFile() to rename "bar.txt" to "foo.txt"
Process 1 uses DeleteFile() to remove "foo2.txt"
Process 2 awakens and displays "This is FOO!"On the filesystem, we then have:
foo.txt containing "This is BAR!"
The good news is that this works fine under NT 4 using just MoveFile(). The bad news is that it requires the files be opened using CreateFile() with the FILE_SHARE_DELETE flag set. The C library which ships with Visual C++ 6 ultimately calls CreateFile() via fopen() but with no opportunity through the standard C library routines to use the FILE_SHARE_DELETE flag. And the FILE_SHARE_DELETE flag cannot be used under Windows 95/98 (Bad Parameter). Which means, on those platforms, there still doesn't appear to be a solution. Under NT/XP/2K, AllocateFile() will have to modified to call CreateFile() instead of fopen(). I'm not sure about ME, but I suspect it behaves similarly to 95/98.
Even two years after Mike's post, the C runtime hasn't got much better. The _fsopen() and _sopen() functions claim to support file sharing, but neither one supports FILE_SHARE_DELETE. For a shell extension, that may not matter; you may just use the Win32 file I/O functions directly. If you want the buffering that the stream I/O functions provide, you can use CreateFile() to open the file with FILE_SHARE_DELETE, then _open_osfhandle() to get a C runtime file descriptor, and _fdopen() to open a stream from that.
Sorry, FILE_SHARE_DELETE doesn't work on 95, 98, or Me; you have to leave the flag off. I'm not sure how you fix this problem for those OSes.
Internet Explorer below 50%
I just saw something amazing in my site stats: Of the browsers that AWStats recognizes (which is most of them), Internet Explorer accounts for fewer than 50% of the visits to mg.to in September.It’s been years since I’ve seen this happen on any site.
This doesn’t include RSS feeds, just browser visits.
Last month, the top browsers were:
70.0% Internet Explorer 13.1% Firefox 5.7% Mozilla 4.4% Opera 3.3% Safari
This month to date, they are:
49.7% Internet Explorer 16.4% Firefox 12.4% Opera 10.9% Mozilla 4.5% Safari
Of course, time will tell if this is a real trend or just the normal fluctuation of a new site. But still, it was cool to see.
Go team! :-)
The great home computer hoax
Rich Manalang posted a hilarious picture yesterday of the home computer of 2004, as envisioned by RAND Corporation scientists 50 years ago.
This futuristic photo includes the control panel from a 60’s era nuclear submarine, along with an LA36 DECwriter II from 1974. Quite a feat for the RAND scientists of 1954.
Robert Scoble is not impressed. He’s unsubscribed from Rich’s feed, because he “can’t trust what goes on his blog anymore.”
I had a similar feeling of outrage the first time I saw Wallace and Gromit in A Grand Day Out. This is the story where Wallace runs out of cheese and builds a rocketship to go to the moon and get some. After all, Wallace says, “everyone knows the moon is made of cheese.”
Well, I found out later that the moon is NOT made of cheese! This just ruined the credibility of the makers of this movie. How dare they try to pull that kind of hoax! Plus, their “actors” didn’t even look real. I promptly decided I’d never watch another Wallace and Gromit movie again.
(But let me know when this one is released, OK?)
Update: I forgot to add a link to Scott Mayo, who posted the image that Rich found.
{kind=link}
Invisible JavaScript functions
If you’re writing document-level JavaScript code in a PDF file, any variables you declare or assign to outside a function are created in the global object, which is the PDF document.
Suppose we have a PDF with this code as a document script, which creates three variables in three different ways:
If we load this PDF and examine its variables in the JavaScript console, we see that each of the three variables is defined both as a global variable and as a property of this, the document object. That seems surprising until you consider that in Acrobat JavaScript, the document object is the global object.
myVar 11 this.myVar 11 myNoVar 22 this.myNoVar 22 myProp 33 this.myProp 33(Keyboard input is in
bold, and we type Ctrl+Enter at the end of each line to evaluate the expression.)
When you’re writing code, you don’t want to pollute the document object’s namespace needlessly. You can wrap up your code in a function, so that variables you create with a var statement are local to the function.
Adobe Acrobat encourages this by creating a function for you when you add a document script. If you use Acrobat’s Document JavaScripts dialog to add a script called DocScript, you’ll get an empty function to fill in:
doc instead of this. We didn’t have to do that, but I like to be able to use doc.whatever instead of this.whatever for document properties.
If we look at these variables in the console window, the results are different:
myVar1 ReferenceError: myVar1 is not defined 1:Console:Exec undefined this.myVar1 undefined myNoVar1 22 this.myNoVar1 22 myProp1 33 this.myProp1 33As expected,
myVar1 does not show up either in the global object or the document object; it is local to the function. myVar2 does (because we didn’t use var), as does myProp1 (because we created it as a property of the doc object).
The difference between myVar1 and this.myVar1 is expected too. It’s an error to reference a variable name that does not exist, so myVar1 throws a ReferenceError exception. But it’s not an error to reference a nonexistent property of an object—the reference merely returns the undefined value. So this.myVar1 returns undefined without error.
But we’ve still put one name in the document object:
DocScript
function DocScript(doc) {
var myVar1 = 11;
myNoVar1 = 22;
doc.myProp1 = 33;
}
this.DocScript
function DocScript(doc) {
var myVar1 = 11;
myNoVar1 = 22;
doc.myProp1 = 33;
}
To avoid even this bit of namespace clutter, we can define an anonymous function and call it on the spot:
The console results for myVar2, etc. are the same as the previous example with the named function, so I won’t repeat them. But unlike the named function, we haven’t added any symbols at all to the document or global object.
Why the extra parentheses? function(){} is the simplest possible anonymous function, but if we try to call it using function(){}() it’s a syntax error. However, if we wrap the entire function inside a pair of parentheses, then we can follow that with () to call it: (function(){})() is legal JavaScript.
The same trick works when you want to add a nested scope inside a function. The way you would do this in C doesn’t work in JavaScript:
That code prints:
1 2 2
because there is only one variable named i in the entire function, even though we’ve (incorrectly) tried to add an inner scope with its own variable i.
In fact, if you load that function into ActiveState Komodo, it puts a green squiggly line under the inner var i = 2; complaining “strict warning: redeclaration of var i”.
But if we use a nested anonymous function:
it prints:
1 2 1
which indicates that the nested function introduced a new scope.
Bad Eggs
Do you have static objects that dynamically allocate memory at startup and carefully free it when your app exits? I’ve used them in a few projects—more than I’d want to admit.
If you’re throwing out a carton of bad eggs, you could take the eggs out of the carton and put them in the trash one by one, followed by the empty carton. But it’s quicker and easier to just toss the whole thing in the trash.
Static objects are bad eggs.
I suppose the C++ runtime has to toss them all in the trash—call their destructors—because it doesn’t know if those destructors really need to be run. But if they’re just going to free memory there ought to be some way to skip all that.
Did you forget your password AGAIN?
If you’re old enough, you may remember when software tried to be “user friendly.” This was before we had Interaction Designers, Usability Consultants, and the like. Nobody was quite sure what “user friendly” was supposed to mean, but it sounded like a good idea.
Sometimes it meant “easy to learn and use”, and that was a good idea. Other times it meant “be friendly to the user”. That didn’t always work out so well.
Windows XP tries hard to be friendly, but there’s one place where it annoys the heck out of me. No, it’s not the doggie who does tricks when you search for a file.
It’s the error message when I mistype my password at the Welcome screen:
Every time I see that, I have to stop myself from reading it as “Did you forget your password AGAIN?” And I want to reply, “No, I didn’t forget my password, you blithering idiot, I mistyped it! Do you have a problem with that?”
Then I remember it’s just a computer, it doesn’t know any better, so I just have to excuse its poor manners.
Why you have to shred that hard drive
This may be old news, but it was new news to me, at least in this kind of detail.
How they read your data after you’ve erased it.
I keep forgetting that hard drives don’t store bits, but store magnetism, a much less precise science.
Remember The Conversation, anyone?
IBM firmware update can wreck your ThinkPad
Matt from the ThinkPad mailing list found this out the hard way: Do not install the latest Embedded Controller Update on your ThinkPad if you have a non-IBM replacement battery, or your machine will no longer work on battery power. This new firmware update checks the battery status in a way that fails with non-IBM batteries.
The version number for the bad update varies for different models, but check the release notes for a phrase like “Enhancement of the battery control.”
The problem affects at least the A30/A30p and A31/A31p models, and possibly others.
Matt’s report is here:
A30/p Embedded Controller Update = Danger, Will Robinson!
Adding insult to injury, the way to fix the problem is to downgrade to the previous version of the Embedded Controller firmware, but you to do this, you need:
- A copy of the previous version for your machine. (And where do you get that?)
- A floppy drive. (The non-diskette version doesn’t work.)
- A charged battery—which means a fresh IBM battery, because your ThinkPad no longer trusts the non-IBM battery!
I’m a huge ThinkPad fan; I just hope this battery incompatibility is an inadvertent bug and that IBM will fix it quickly.
WiFi Desert
Following up on his Windows XP SP2 report, John Levanger explains how they get wireless Internet in the Afghan desert:
Technology has changed the way we do business in the military. It does seem somewhat bizarre to have unfettered internet access in the middle of nowhere. I can sit in my tent with my ThinkPad and email, IM, and browse the internet the same as if I was sitting in my living room back in Georgia. Myself and 39 other buddies purchased a satellite system from an outfit out of India. The ISP is actually in Germany and we get just about T1 bandwidth which is split up 40 ways if everyone is on (which doesn’t occur due to different work shifts). We “beam” it out via Wi-Fi to the different tents. Even our aircraft (I’m in a CH-47 Chinook unit) are on an intranet of sorts. The system called Blue Force Tracker allows secure tracking of all the different aircraft (and ground elements) within the theater real time. We can email between aircraft and to our headquarters during flight…all with satellite technology. I’ve hardly sent a snail mail letter since I’ve been here. SSG John Levanger Taskforce Diamondhead Kandahar, Afghanistan “People sleep comfortably at night in their beds only because rough men stand ready to do violence in their behalf”.
(From the ThinkPad mailing list.)
Cancel to Continue
Seen in a web application, after I clicked a link to go to a different page:
Energizer Project: Keeps Building and Building
Did you ever have a Visual C++ project that won’t stop building? It builds OK, but if you start the debugger or do another Ctrl+Shift+B, it says it’s out of date and wants to build again? Every time?
This happened to me and I was stumped. There was nothing in the Output window to tell me what was wrong. It looked like a perfectly successful build:
------ Build started: Project: Test,
Configuration: Debug Win32 ------
Compiling resources...
Linking...
Build log was saved at
"file://c:\Test\Debug\BuildLog.htm"
Test - 0 error(s), 0 warning(s)
-------------- Done --------------
Build: 1 succeeded, 0 failed, 0 skipped
The only problem was it compiled those resources every time. It never thought they were up to date.
I tried some Google searches. Nothing. This was annoying me, and the rest of my team.
Finally, out of sheer frustration, I Ctrl+clicked on that “Build log” link, like the helpful tooltip suggested.
Oh. Now it tells me:
Compiling resources... Linking... Test : warning PRJ0041 : Cannot find missing dependency 'ICON_FILE' for file 'Test.rc'. Your project may still build, but may continue to appear out of date until this file is found.
That gives me a desperately needed clue. Looking at Test.rc, I see that I’d coded:
Well, it sounded like a good idea at the time, honest.
The resource compiler has no problem with this, but apparently the dependency checker can’t handle it.
Changing it to this fixed it:
The Moral:
- The information you need may be hiding behind a link. Just because the Output window has always told you about build problems doesn’t mean it will tell you today.
- If your product has an Output window that almost always provides complete information, fix it so it always does.
A Typical XP SP2 Upgrade
Just your everyday XP SP2 installation report. Be sure to read to the end…
(From the ThinkPad mailing list.)
NULL hInstance Considered Harmful
On a couple of occasions, I've converted large Windows applications from EXEs to DLLs which are loaded by stub EXEs. There are several reasons you might want to do this, and for the most part it's surprisingly easy. Most Windows code doesn't know or care if it's running in a DLL or EXE, as long as it has the right instance handle for any functions that load resources or the like.
There were a few Windows functions that gave us grief, though. These are the functions that accept a NULL hInstance to mean the current process. I used to think this was a nice convenience, but all the code that used a NULL hInstance had to be converted to take an explicit hInstance.
I searched for the functions that came to mind and fixed them:
GetModuleBaseName
GetModuleFileName
GetModuleHandle
But I forgot about an entire group of functions and had to find them the hard way, through some tedious debugging:
EnumResourceLanguages
EnumResourceNames
EnumResourceTypes
FindResource
FindResourceEx
FindResourceWrapW
LoadResource
Are there more functions like this?
A Dog named dog?
In many programming languages, it’s a popular convention—or even a language rule—that class names begin with a capital letter and class instances begin with a lowercase letter. For example, you might have a Dog class and a particular instance of that class named dog. In other words, you have a Dog named dog, and dog is a Dog.
I just accepted that as the normal state of affairs, until I read my daughter her new book Just Dog.
Just Dog begins:
“Dog was a dog and that’s what everyone called him. Dog. Just Dog.”
Now wait a minute. The story doesn’t say dog is a Dog, it says Dog is a dog.
Come to think of it, I’m not a Person named mike, I’m a person named Mike.
So why do we use a naming convention in programming that is the exact opposite of how we name things in the real world?
And even more puzzling, why does it feel right?
Ruby iterators and C callback functions
Mike Sax wonders what’s the fuss about iterators. Aren’t they just a fancy use of function pointers? Indeed, Mike has hit the nail on the head. Consider the window iterator that’s been built into Windows since 1.0:
This function iterates through all of the top-level windows (children of the desktop window) and calls lpEnumFunc for each one, passing it the HWND of each window and the lParam that you passed to EnumWindows.
So lParam is how you get to provide some state that the enumeration function can make use of. Suppose you wanted to write a function that counted the number of visible top-level windows. Your C code might look like this:
This works, but it is rather tedious. So Windows 2.0 added the GetWindow function, which lets you simply ask for a window’s child or next sibling. That simplifies the overall structure of the code, especially if you use the GetFirstChild and GetNextSibling macros defined in windowsx.h:
That’s it, just one function, no callback function or struct definition needed. We don’t need the struct because the code inside the loop can directly reference the nVisible variable defined in the function.
But the simplification came at a price: We had to write the loop ourselves, asking explicitly for the first child of the desktop window and then the next sibling of each child window.
Also, it doesn’t work.
What if another application creates or destroys a top-level window, or just changes a window’s Z-order, while you’re in the loop? You’ll either miss a window, count one twice, or crash with an invalid window handle.
To handle these cases, you need a bit more complexity. If you had a way to temporarily lock all window creation and destruction, you could quickly create a list of all the windows and then release the lock, then enumerate from that list, perhaps also doing a last-minute check when you enumerate each window to skip any that get destroyed during enumeration. Or, you might set a Windows hook to notify you of any windows created, destroyed, or moved in the Z-order, so you could deal with them appropriately.
Whatever you did, it would be enough code that you wouldn’t want to duplicate it each time you wanted to write a window loop. The GetFirstChild/GetNextSibling style of loop doesn’t really facilitate that kind of code isolation. The EnumWindows style enumerator completely separates the code that does the iterating (EnumWindows itself) from the code that receives the iteration (your callback function). But, it makes it harder to share state between the callback function and the code that called EnumWindows.
If you had a way to use a callback function, but have it more easily share state with the calling function, you’d have a winner. In C# and JavaScript, you can do this by using an anonymous callback function nested inside the surrounding code. Because of lexical scoping, the callback function can access variables in the parent function as easily as it can access its own.
Both those language have enough extra syntactic cruft that when you look at a simple example using nested anonymous functions, it’s easy to be unimpressed. The payoff shows up in more complicated, real-life coding situations.
Code blocks in Ruby simplify this technique down to its essence, making it useful even for simple cases. Assuming a good Rubyesque Windows interface library, our function might be something like:
In this code, the enumWindows function takes a code block argument and calls that code block for each window, passing it the window as an argument. Because the code block is nested inside the countVisibleWindows function, it can access the nVisible variable directly.
This solves both our problems: The logic for iterating through the windows is separated out into the enumWindows function, and the callback function (code block) can access state variables cleanly and easily.
(In Ruby, a code block is a like a callback function, but it’s not quite a full-fledged function. A code block does not introduce a new scope for variables—it shares the scope of the enclosing function.)
Unfortunately, Ruby does not seem to have a Windows interface library that works like this. Ruby’s standard Win32 module provides a general way to call Windows DLL functions, but it doesn’t have a clean implementation of enumWindows that uses a code block.
However, MoonWolf has written a Ruby port of Perl’s Win32::GuiTest module that includes this kind of enumWindows function. It’s implemented in two parts: a low level function written in C that enumerates HWND values, and a higher level function written in Ruby that constructs Ruby window objects and enumerates them. The window object in Win32::GuiTest is a fairly thin wrapper that encapsulates an HWND and other window information.
The high-level enumWindows looks like this:
This code calls the low-level _enumWindows function, which passes an HWND to the code block enclosed in curly braces. This code block creates the window object, appends to the ret array, and also yields the window object to a code block that was provided by the caller of enumWindows.
If I were implementing this, I think I would change it a bit. Typically a function like this either yields results to a code block, or it returns a value, but not both. And I would change the confusingly named createWindow function (which has no relation to the CreateWindow function in Windows):
Either way, our countVisibleWindows example ends up pretty much as I’d imagined:
The low-level enumWindows function that enumerates HWND values is implemented in C. The initialization code to add the enumWindows function is simply:
where mGuiTest is a reference to the Win32::GuiTest module.
The guitest_enumWindows function is:
and the EnumWindowsProc callback is:
This shows how easy it is to extend Ruby with C code, adding functions that work just like ones written in Ruby.
So, how do all the calls and callbacks stack up when we run the countVisibleWindows function? Something like this:
enumWindows
_enumWindows
EnumWindows
EnumWindowsProc
rb_yield
(code block in enumWindows)
yield
(code block in
countVisibleWindows)
In everyday use, of course, you don’t worry about that whole call stack, just the part of it you’re working with.
Use elementsof(sz), not sizeof(sz)
I had to fix a bug recently where my shell extension was crashing another application when you used that app’s File Open dialog.
This application has a thumbnail view of the selected file in the File Open dialog, which they generate the same way as Windows Explorer: by loading a shell extension for the selected filetype and calling its IExtractImage interface. It’s a fairly weird protocol: First they call your IPersistFile::Load to give you the filename, then you give them back the same filename when they call IExtractImage::GetLocation. Finally they call IExtractImage::Extract and that’s when you generate the thumbnail.
But, after my GetLocation method returned, the application silently exited. What could be wrong? My code worked fine in Explorer.
GetLocation is a typical function that takes a character string buffer and length along with some other parameters (omitted here):
I noticed that this other app was giving me an unusually large file pathname buffer, 520 characters or 1040 bytes to be exact. This number sounded strangely familiar (and not just because of this).
Then I realized what happened. I’ve never seen the source code for this app I was crashing, but I just know it looked like this:
Oops. The cchMax argument to GetLocation is a length in characters, but sizeof gives you the size in bytes. And we’re talking WCHAR here, so each character is two bytes. MAX_PATH is 260, making szPath 520 bytes long, the number that they passed into my code.
One way to fix the problem is:
That gives correct code, but I never like seeing MAX_PATH repeated like this. sizeof is in the right spirit, actually measuring the array length instead of repeating a constant, but it measures the wrong thing, bytes instead of characters (array elements).
I like to code this with the elementsof macro, defined as:
Then you can just use elementsof instead of sizeof:
elementsof is handy anytime you need the length of a character string array or any array.
Of course, I didn’t have the luxury of fixing this code at its source (other than reporting the bug to the program’s authors). So I worked around it by checking for the bogus 520 character cchMax and cutting it back to 260 (MAX_PATH) characters.
More C#, Ruby, and Python Iterators, and JavaScript too
Making a valiant attempt to post code with my comment system (Sorry, Mike! :-(), Mike Roome points out:
The ruby example isn
Iterators in C#, Python, and Ruby
Matt Pietrek marvels at C# 2.0 iterators and dissects them right down to the CLR bytecode. I always learn something from Matt, and this whirlwind tour is no exception.
Matt says, “This was the beginning of my descent into the loopy world of C# 2.0 iterators. It took me awhile to wrap my head around them, and when I tried to explain them to other team members I got looks of total confusion.” I wonder if it would have been less confusing if Matt’s team had first been exposed to yield iterators in a language that makes them easier to use.
After using Python and Ruby, the iterators in C# feel right at home to me. They work the same in all three languages, but in Ruby and Python there’s not as much other code to get in the way of understanding them.
Let’s combine all of Matt’s examples into one, and compare the code in each language. First, in C#:
When you run that, it should print:
First
After First
0
1
2
Before Last
Last
After Last
Here’s how you would write the same code in Python:
And in Ruby, the code looks like this:
The one unfamiliar thing here may be the |name| notation, which is how a code block such as the body of a loop receives its argument. And the p statements are a kind of print statement.
This Ruby version is even more concise and equally readable once you’re comfortable with the |name| notation:
Either way, the Python and Ruby versions make it easier to see what the iterator function does and how yield interacts with the rest of the code.
You may note that the Python and Ruby versions don’t create and instantiate a SomeContainer class as the C# version does. That’s true, and it would make the code in those languages a bit longer (but still simpler than the C# code). But, if you don’t need to—and you especially don’t need to when you’re experimenting and trying to understand a radical new technique like yield iterators—why bother?
WordPress: Thanks!
I needed a blog, and I needed it fast. I wanted something written in Ruby or maybe Python, but I’d heard enough good things about WordPress that I gave it a try.
Wow! This is nice work! I’ll live with it being written in PHP. ;-) It was easy to get running on my virtual Linux server, once I figured out how to add a MySQL user for WordPress. The default stylesheet stinks big-time, but the WordPress Wiki pointed me to the Style Competition, where I found the Rubric style was closest to my taste. I tweaked it a bit and here we are.