Programming
DOM creation: good, bad, and ugly
The Ajaxians are talking about a new $E function that is supposed to make it easier to create DOM elements. The example given creates the equivalent of this HTML code:
using this code to do it:
That seems just a tad complicated! Let’s see how it would look using my DOM creator for jQuery and Prototype:
Ah, that is quite a bit simpler. It’s also more flexible. Suppose you want to save a reference to that A tag in the middle. There’s no way to do that with $E, but it can be as easy as this:
Easy DOM creation for jQuery and Prototype
Here is a jQuery plugin that makes it easy to build up a tree of DOM nodes. It lets you write code like this:
Basically, each function such as $.TABLE creates a DOM node and takes the following arguments:
The first argument is an object that list any attributes to be set on the node. You can specify the className attribute in a few different ways depending on your taste:
Any additional arguments after the first one represent child nodes to be created and appended. These arguments can be DOM elements themselves (e.g. inline $.FOO calls as above), or they can be numbers or strings which are converted to text nodes, or they can be arrays, in which case each element of the array is handled in this same way.
This interface is inspired by Bob Ippolito’s MochiKit DOM API, although it doesn’t implement all of the features of that one (yet).
The code predefines most of the common tags; you can add additional tags by calling:
Or simply add the tag names to the tags list in the code.
One last definition is $.NBSP which defines a non-breaking space (same as in HTML).
$._createNode is an internal helper function used by the $.FOO functions. I would have hidden it away as a nested function, but I wanted to avoid any unnecessary closures.
This code doesn’t actually depend on any of the features of jQuery except for the presence of the $ function—and it uses $ only as a way to avoid cluttering the global namespace. I haven’t tested it with Prototype.js, but it should work equally well there. Or the code can be used with no library, by preceding it with:
Here is the source code, or you can download it:
JSON for jQuery
Update 2007-09-13: As of version 1.2, the jQuery core now supports cross-domain JSONP downloads as part of the native Ajax support. I suggest you use this support instead of the plugin.
jQuery is a nifty new JavaScript library by John Resig. It features a $() function like the one in Prototype.js, but beefed up with CSS and XPath selectors, and with the ability to chain methods to do interesting things with concise code.
Unlike Prototype, jQuery doesn’t mess around with built-in JavaScript objects. It’s new—too new to have a version number!—but I’ve been writing some code with it and enjoying it.
jQuery provides an easy way to write plugin methods to extend the $ function. For you JSON fans out there, here is a JSON plugin for jQuery which lets you write code like this:
You can of course use an anonymous function if you prefer:
Or, using jQuery’s method chaining, you can combine calls like this code which displays a “Loading…” message when it starts loading the JSON resource:
To install the plugin, simply paste this code into a .js file and load it after loading jquery.js:
This adds a json() method to the $ function. The first argument is the URL to the JSON resource, with the text {callback} wherever the JSON callback method should be provided. In a JSONP URL, you would use jsonp={callback}; in a Yahoo! JSON URL you would use format=json&callback={callback}.
The second argument is the callback function itself. When the JSON resource finishes loading, this function will be called with a single argument, the JSON object itself. Inside the callback function, this is a reference to the HTML element found by the $ function. (If $ found more than one element, the callback function is called for each of them.)
The callback function is required, so this code won’t work with plain JSON APIs like del.icio.us that don’t let you specify a callback function. This would be easy enough to fix; I didn’t need it for the code I was writing, and didn’t think of it until just now. :-)
The code goes to a bit of extra work to create both an array entry and a unique global name for each callback. The global name is what is substituted into the {callback} part of the URL. It uses this name instead of the array reference to ensure compatibility with any JSON APIs that don’t allow special characters in the callback name. In fact, in the current code the callbacks[] array entries are not really used, but I figured it could be handy to have an array of all outstanding callbacks.
Update: John Resig suggested a couple of improvements to the code, so it’s updated, simpler and better now.
Update 2: Code updated to include Stephen and Brent’s fixes from the comments.
Ajax-style PDF part 1: fading highlight setup
If you haven’t already seen it, take a look at Adobe’s walking talking PDF tour of Acrobat 7.0. It’s one of the most creative PDF files I’ve ever seen. (Don’t stop after the first few pages; there are some funny bits near the end.)

Obviously, a lot of work went into making this PDF, but the technical side of it is actually pretty simple. We can add some scripting magic to make it even better.
Take page 11, where our narrator explains the links he’s standing next to, pointing to each one as he describes it:

The links just sit there when he points at them. It would look good, and be a nice usability touch, if we could apply an Ajax-style fading highlight to each link as he points to it:

First we need to find out how the existing page works. If you have Acrobat Professional, you can see it by using the Select Object tool on the Advanced Editing toolbar. That’s a Flash movie on the right with the narrator in it. Right click it and open its Properties to see the Page Enter event and a .swf rendition (Acrobat’s term for a media clip and its associated settings):
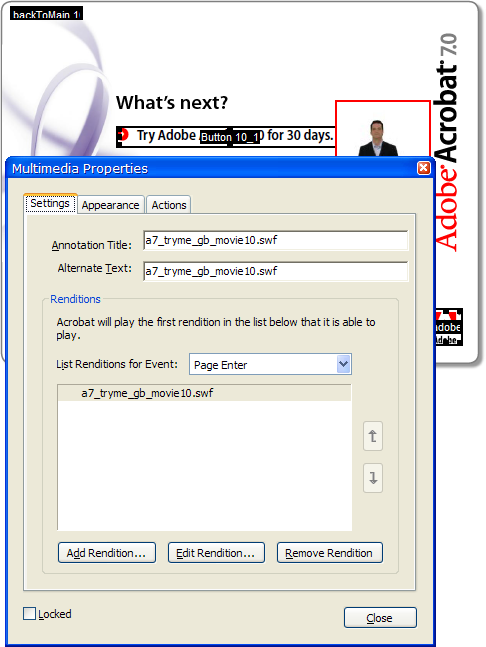
Each page is like this, with a Flash movie embedded in the page that runs on the Page Enter event.
The links on the left are (no surprise) PDF pushbutton form fields.
With our narrator in a Flash movie and the links being PDF buttons, is there a way to connect the two? We can write some JavaScript code in the PDF to fade a highlight on and off for a link, but how do we trigger that code at the right time as the movie plays?
Well, one thing at a time. It would be fun to just see the fading highlight in action, so we’ll write that bit of code first and hook it up to a temporary button to test it. The code will use doc.getField(name) to get a JavaScript Field object, and then it can set the field’s fillColor property to change its background color. If we do that on a repeating fast timer we’ll have the fading highlight effect.
For a quick test before we write any code, we can right click one of the buttons and open its Properties to change its fill color manually:
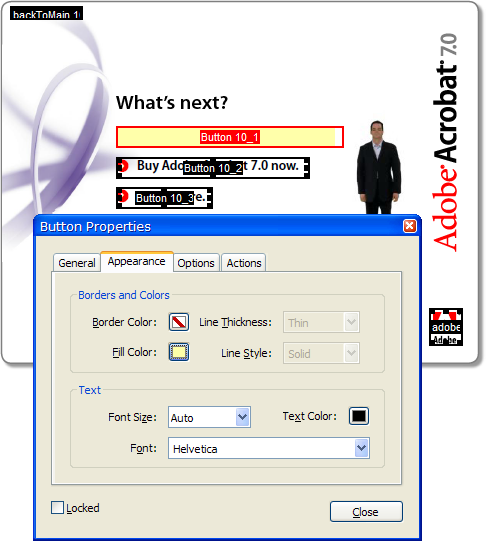
Oops. That worked, but it didn’t do what we want. We got the fill color but the icon and text went away. Let’s Undo it and try something else. (And note that the fill color doesn’t extend all the way to the right end of the field. That’s because the Flash movie overlaps the field. Hopefully this won’t cause any problem.)
We can create a separate field that is a solid rectangle, and if we get the Z-order right it should do what we want. A text field with no text in it will do the trick. Let’s try it without worrying about the exact layout first:
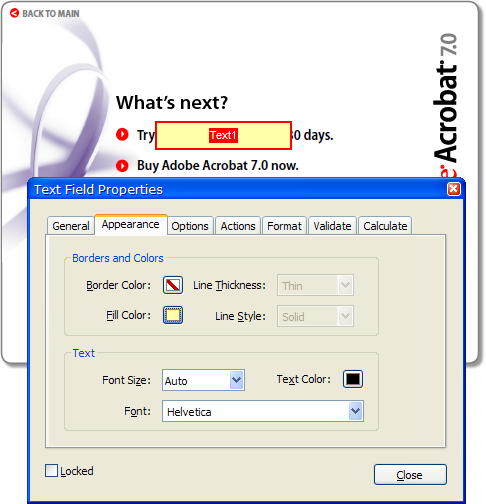
I guess that’s some kind of progress. Maybe changing the Z-order will fix it. The tool to change that is tucked away in Acrobat’s Advanced/Forms/Fields/Set Tab Order menu command:

Now we can click on the fields in order to set their tab order (which is also their Z-order), and if we put the text field in the tab order before the button, we get the transparent background highlight we were looking for:

Finally, we move and resize the text field and we have our field highlight, at least in static form. Here’s the page after a Select All (Ctrl+A) to show all the field rectangles:
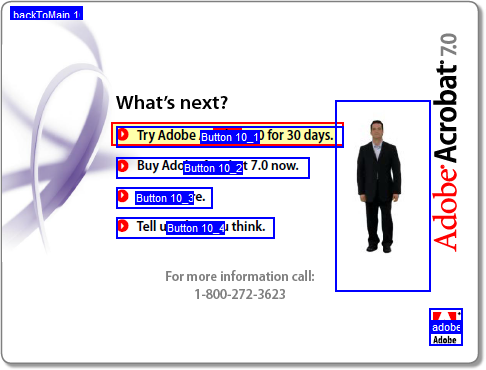
Creating a separate text field for the highlight was a minor nuisance, but does have one benefit: we were able to fine tune the highlight position relative to the button icon and text:

The blue outline is the pushbutton field that we tried to work with originally. As you can see, the pushbutton field rectangle doesn’t have consistent margins around the icon and text (and no margin on the left). With a separate text field—the red outline—we can adjust it so the highlight is positioned nicely:
Now that we have a highlighter field, we should be able to write some code to control it. While I was editing the field I changed its name from the default Text1 to Hilite, so we should be able to use getField and set its fillColor. Let’s try it in the JavaScript console first:
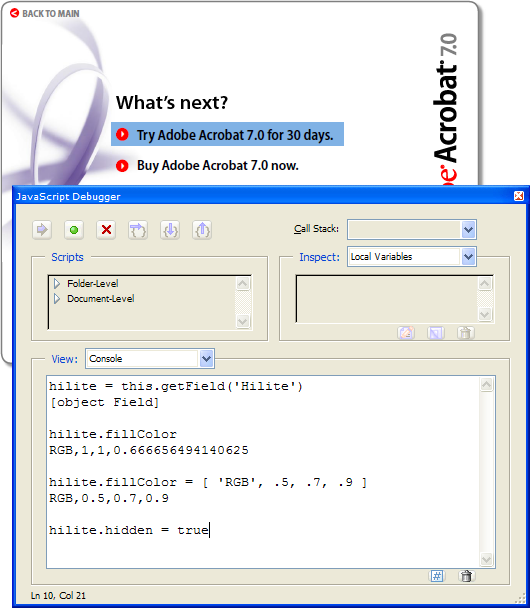
Looks good! We got a reference to the field in the hilite variable and looked at its current fillColor property. Then we changed the fillColor and the visible field changed as expected.
The last statement in the JavaScript console (not yet executed in the screen shot) hides the field, so we can save the file and it looks normal. It doesn’t matter that we left the field the wrong color; we’ll take care of that in the code that makes it visible again. For now, it’s time to save the file and take a break. In the next installment we’ll write some code to create the fading highlight effect.
p.s. Here’s an Acrobat editing tip: Open the General tab of Acrobat’s Preferences dialog and turn on the single-key accelerators. Then you can use the H key for “hand” (normal) mode in Acrobat, R for the object selector, and so on. Hover the mouse over a toolbar button to see its shortcut key. It makes this kind of editing a lot easier where you switch tools so often.
Disclaimer: I work for Adobe, but this is my own summer vacation project, not any kind of offical Adobe code.
Use FILE_SHARE_DELETE in your shell extension
A Windows shell extension that provides information from the contents of a file has to open the file to do it. Opening a file locks it to some extent or another, depending on the file sharing flags you use. Even if you open the file for only a moment, that can be long enough to interfere with another program's use of the file.
What happens when someone drags a file from one folder to another, and you have a shell extension that renders thumbnails for the selected file type? Windows calls your IExtractImage interface and you start rendering the thumbnail. Then as soon as your customer releases the mouse, Windows tries to move the file to the new folder. If they move fast enough, this can happen while you've still got the file open to render the thumbnail. That results in this lovely message:
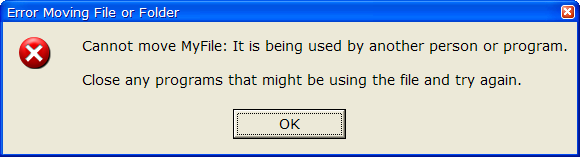
If they're lucky, they'll try again and go a little slower, and it will work! You've finished rendering the thumbnail, closed the file, and Windows can move it with no problem.
There's an easy way to fix this for Windows NT, 2000, and XP. In the CreateFile() call that opens the file, use FILE_SHARE_READ | FILE_SHARE_DELETE in the dwShareMode parameter.
The MSDN documentation doesn't make it clear at all, but FILE_SHARE_DELETE works with MoveFile() in the same way it does with DeleteFile(). In other words, it gives you Unix-style delete/rename semantics. Even while you have the file open, Windows can delete it or rename it right out from under you, but you can keep reading it—your handle to the file remains valid until you close it.
So, in the case above, Windows moves the file to the destination folder without interference from your thumbnail code.
Mike Mascari ran a test of this and posted the results in the comp.databases.postgresql.hackers newsgroup:
Well, here's the test:
foo.txt contains "This is FOO!"
bar.txt contains "This is BAR!"Process 1 opens foo.txt
Process 2 opens foo.txt
Process 1 sleeps 7.5 seconds
Process 2 sleeps 15 seconds
Process 1 uses MoveFile() to rename "foo.txt" to "foo2.txt"
Process 1 uses MoveFile() to rename "bar.txt" to "foo.txt"
Process 1 uses DeleteFile() to remove "foo2.txt"
Process 2 awakens and displays "This is FOO!"On the filesystem, we then have:
foo.txt containing "This is BAR!"
The good news is that this works fine under NT 4 using just MoveFile(). The bad news is that it requires the files be opened using CreateFile() with the FILE_SHARE_DELETE flag set. The C library which ships with Visual C++ 6 ultimately calls CreateFile() via fopen() but with no opportunity through the standard C library routines to use the FILE_SHARE_DELETE flag. And the FILE_SHARE_DELETE flag cannot be used under Windows 95/98 (Bad Parameter). Which means, on those platforms, there still doesn't appear to be a solution. Under NT/XP/2K, AllocateFile() will have to modified to call CreateFile() instead of fopen(). I'm not sure about ME, but I suspect it behaves similarly to 95/98.
Even two years after Mike's post, the C runtime hasn't got much better. The _fsopen() and _sopen() functions claim to support file sharing, but neither one supports FILE_SHARE_DELETE. For a shell extension, that may not matter; you may just use the Win32 file I/O functions directly. If you want the buffering that the stream I/O functions provide, you can use CreateFile() to open the file with FILE_SHARE_DELETE, then _open_osfhandle() to get a C runtime file descriptor, and _fdopen() to open a stream from that.
Sorry, FILE_SHARE_DELETE doesn't work on 95, 98, or Me; you have to leave the flag off. I'm not sure how you fix this problem for those OSes.
Invisible JavaScript functions
If you’re writing document-level JavaScript code in a PDF file, any variables you declare or assign to outside a function are created in the global object, which is the PDF document.
Suppose we have a PDF with this code as a document script, which creates three variables in three different ways:
If we load this PDF and examine its variables in the JavaScript console, we see that each of the three variables is defined both as a global variable and as a property of this, the document object. That seems surprising until you consider that in Acrobat JavaScript, the document object is the global object.
myVar 11 this.myVar 11 myNoVar 22 this.myNoVar 22 myProp 33 this.myProp 33(Keyboard input is in
bold, and we type Ctrl+Enter at the end of each line to evaluate the expression.)
When you’re writing code, you don’t want to pollute the document object’s namespace needlessly. You can wrap up your code in a function, so that variables you create with a var statement are local to the function.
Adobe Acrobat encourages this by creating a function for you when you add a document script. If you use Acrobat’s Document JavaScripts dialog to add a script called DocScript, you’ll get an empty function to fill in:
doc instead of this. We didn’t have to do that, but I like to be able to use doc.whatever instead of this.whatever for document properties.
If we look at these variables in the console window, the results are different:
myVar1 ReferenceError: myVar1 is not defined 1:Console:Exec undefined this.myVar1 undefined myNoVar1 22 this.myNoVar1 22 myProp1 33 this.myProp1 33As expected,
myVar1 does not show up either in the global object or the document object; it is local to the function. myVar2 does (because we didn’t use var), as does myProp1 (because we created it as a property of the doc object).
The difference between myVar1 and this.myVar1 is expected too. It’s an error to reference a variable name that does not exist, so myVar1 throws a ReferenceError exception. But it’s not an error to reference a nonexistent property of an object—the reference merely returns the undefined value. So this.myVar1 returns undefined without error.
But we’ve still put one name in the document object:
DocScript
function DocScript(doc) {
var myVar1 = 11;
myNoVar1 = 22;
doc.myProp1 = 33;
}
this.DocScript
function DocScript(doc) {
var myVar1 = 11;
myNoVar1 = 22;
doc.myProp1 = 33;
}
To avoid even this bit of namespace clutter, we can define an anonymous function and call it on the spot:
The console results for myVar2, etc. are the same as the previous example with the named function, so I won’t repeat them. But unlike the named function, we haven’t added any symbols at all to the document or global object.
Why the extra parentheses? function(){} is the simplest possible anonymous function, but if we try to call it using function(){}() it’s a syntax error. However, if we wrap the entire function inside a pair of parentheses, then we can follow that with () to call it: (function(){})() is legal JavaScript.
The same trick works when you want to add a nested scope inside a function. The way you would do this in C doesn’t work in JavaScript:
That code prints:
1 2 2
because there is only one variable named i in the entire function, even though we’ve (incorrectly) tried to add an inner scope with its own variable i.
In fact, if you load that function into ActiveState Komodo, it puts a green squiggly line under the inner var i = 2; complaining “strict warning: redeclaration of var i”.
But if we use a nested anonymous function:
it prints:
1 2 1
which indicates that the nested function introduced a new scope.
Bad Eggs
Do you have static objects that dynamically allocate memory at startup and carefully free it when your app exits? I’ve used them in a few projects—more than I’d want to admit.
If you’re throwing out a carton of bad eggs, you could take the eggs out of the carton and put them in the trash one by one, followed by the empty carton. But it’s quicker and easier to just toss the whole thing in the trash.
Static objects are bad eggs.
I suppose the C++ runtime has to toss them all in the trash—call their destructors—because it doesn’t know if those destructors really need to be run. But if they’re just going to free memory there ought to be some way to skip all that.
Energizer Project: Keeps Building and Building
Did you ever have a Visual C++ project that won’t stop building? It builds OK, but if you start the debugger or do another Ctrl+Shift+B, it says it’s out of date and wants to build again? Every time?
This happened to me and I was stumped. There was nothing in the Output window to tell me what was wrong. It looked like a perfectly successful build:
------ Build started: Project: Test,
Configuration: Debug Win32 ------
Compiling resources...
Linking...
Build log was saved at
"file://c:\Test\Debug\BuildLog.htm"
Test - 0 error(s), 0 warning(s)
-------------- Done --------------
Build: 1 succeeded, 0 failed, 0 skipped
The only problem was it compiled those resources every time. It never thought they were up to date.
I tried some Google searches. Nothing. This was annoying me, and the rest of my team.
Finally, out of sheer frustration, I Ctrl+clicked on that “Build log” link, like the helpful tooltip suggested.
Oh. Now it tells me:
Compiling resources... Linking... Test : warning PRJ0041 : Cannot find missing dependency 'ICON_FILE' for file 'Test.rc'. Your project may still build, but may continue to appear out of date until this file is found.
That gives me a desperately needed clue. Looking at Test.rc, I see that I’d coded:
Well, it sounded like a good idea at the time, honest.
The resource compiler has no problem with this, but apparently the dependency checker can’t handle it.
Changing it to this fixed it:
The Moral:
- The information you need may be hiding behind a link. Just because the Output window has always told you about build problems doesn’t mean it will tell you today.
- If your product has an Output window that almost always provides complete information, fix it so it always does.
NULL hInstance Considered Harmful
On a couple of occasions, I've converted large Windows applications from EXEs to DLLs which are loaded by stub EXEs. There are several reasons you might want to do this, and for the most part it's surprisingly easy. Most Windows code doesn't know or care if it's running in a DLL or EXE, as long as it has the right instance handle for any functions that load resources or the like.
There were a few Windows functions that gave us grief, though. These are the functions that accept a NULL hInstance to mean the current process. I used to think this was a nice convenience, but all the code that used a NULL hInstance had to be converted to take an explicit hInstance.
I searched for the functions that came to mind and fixed them:
GetModuleBaseName
GetModuleFileName
GetModuleHandle
But I forgot about an entire group of functions and had to find them the hard way, through some tedious debugging:
EnumResourceLanguages
EnumResourceNames
EnumResourceTypes
FindResource
FindResourceEx
FindResourceWrapW
LoadResource
Are there more functions like this?
A Dog named dog?
In many programming languages, it’s a popular convention—or even a language rule—that class names begin with a capital letter and class instances begin with a lowercase letter. For example, you might have a Dog class and a particular instance of that class named dog. In other words, you have a Dog named dog, and dog is a Dog.
I just accepted that as the normal state of affairs, until I read my daughter her new book Just Dog.
Just Dog begins:
“Dog was a dog and that’s what everyone called him. Dog. Just Dog.”
Now wait a minute. The story doesn’t say dog is a Dog, it says Dog is a dog.
Come to think of it, I’m not a Person named mike, I’m a person named Mike.
So why do we use a naming convention in programming that is the exact opposite of how we name things in the real world?
And even more puzzling, why does it feel right?
Ruby iterators and C callback functions
Mike Sax wonders what’s the fuss about iterators. Aren’t they just a fancy use of function pointers? Indeed, Mike has hit the nail on the head. Consider the window iterator that’s been built into Windows since 1.0:
This function iterates through all of the top-level windows (children of the desktop window) and calls lpEnumFunc for each one, passing it the HWND of each window and the lParam that you passed to EnumWindows.
So lParam is how you get to provide some state that the enumeration function can make use of. Suppose you wanted to write a function that counted the number of visible top-level windows. Your C code might look like this:
This works, but it is rather tedious. So Windows 2.0 added the GetWindow function, which lets you simply ask for a window’s child or next sibling. That simplifies the overall structure of the code, especially if you use the GetFirstChild and GetNextSibling macros defined in windowsx.h:
That’s it, just one function, no callback function or struct definition needed. We don’t need the struct because the code inside the loop can directly reference the nVisible variable defined in the function.
But the simplification came at a price: We had to write the loop ourselves, asking explicitly for the first child of the desktop window and then the next sibling of each child window.
Also, it doesn’t work.
What if another application creates or destroys a top-level window, or just changes a window’s Z-order, while you’re in the loop? You’ll either miss a window, count one twice, or crash with an invalid window handle.
To handle these cases, you need a bit more complexity. If you had a way to temporarily lock all window creation and destruction, you could quickly create a list of all the windows and then release the lock, then enumerate from that list, perhaps also doing a last-minute check when you enumerate each window to skip any that get destroyed during enumeration. Or, you might set a Windows hook to notify you of any windows created, destroyed, or moved in the Z-order, so you could deal with them appropriately.
Whatever you did, it would be enough code that you wouldn’t want to duplicate it each time you wanted to write a window loop. The GetFirstChild/GetNextSibling style of loop doesn’t really facilitate that kind of code isolation. The EnumWindows style enumerator completely separates the code that does the iterating (EnumWindows itself) from the code that receives the iteration (your callback function). But, it makes it harder to share state between the callback function and the code that called EnumWindows.
If you had a way to use a callback function, but have it more easily share state with the calling function, you’d have a winner. In C# and JavaScript, you can do this by using an anonymous callback function nested inside the surrounding code. Because of lexical scoping, the callback function can access variables in the parent function as easily as it can access its own.
Both those language have enough extra syntactic cruft that when you look at a simple example using nested anonymous functions, it’s easy to be unimpressed. The payoff shows up in more complicated, real-life coding situations.
Code blocks in Ruby simplify this technique down to its essence, making it useful even for simple cases. Assuming a good Rubyesque Windows interface library, our function might be something like:
In this code, the enumWindows function takes a code block argument and calls that code block for each window, passing it the window as an argument. Because the code block is nested inside the countVisibleWindows function, it can access the nVisible variable directly.
This solves both our problems: The logic for iterating through the windows is separated out into the enumWindows function, and the callback function (code block) can access state variables cleanly and easily.
(In Ruby, a code block is a like a callback function, but it’s not quite a full-fledged function. A code block does not introduce a new scope for variables—it shares the scope of the enclosing function.)
Unfortunately, Ruby does not seem to have a Windows interface library that works like this. Ruby’s standard Win32 module provides a general way to call Windows DLL functions, but it doesn’t have a clean implementation of enumWindows that uses a code block.
However, MoonWolf has written a Ruby port of Perl’s Win32::GuiTest module that includes this kind of enumWindows function. It’s implemented in two parts: a low level function written in C that enumerates HWND values, and a higher level function written in Ruby that constructs Ruby window objects and enumerates them. The window object in Win32::GuiTest is a fairly thin wrapper that encapsulates an HWND and other window information.
The high-level enumWindows looks like this:
This code calls the low-level _enumWindows function, which passes an HWND to the code block enclosed in curly braces. This code block creates the window object, appends to the ret array, and also yields the window object to a code block that was provided by the caller of enumWindows.
If I were implementing this, I think I would change it a bit. Typically a function like this either yields results to a code block, or it returns a value, but not both. And I would change the confusingly named createWindow function (which has no relation to the CreateWindow function in Windows):
Either way, our countVisibleWindows example ends up pretty much as I’d imagined:
The low-level enumWindows function that enumerates HWND values is implemented in C. The initialization code to add the enumWindows function is simply:
where mGuiTest is a reference to the Win32::GuiTest module.
The guitest_enumWindows function is:
and the EnumWindowsProc callback is:
This shows how easy it is to extend Ruby with C code, adding functions that work just like ones written in Ruby.
So, how do all the calls and callbacks stack up when we run the countVisibleWindows function? Something like this:
enumWindows
_enumWindows
EnumWindows
EnumWindowsProc
rb_yield
(code block in enumWindows)
yield
(code block in
countVisibleWindows)
In everyday use, of course, you don’t worry about that whole call stack, just the part of it you’re working with.
Use elementsof(sz), not sizeof(sz)
I had to fix a bug recently where my shell extension was crashing another application when you used that app’s File Open dialog.
This application has a thumbnail view of the selected file in the File Open dialog, which they generate the same way as Windows Explorer: by loading a shell extension for the selected filetype and calling its IExtractImage interface. It’s a fairly weird protocol: First they call your IPersistFile::Load to give you the filename, then you give them back the same filename when they call IExtractImage::GetLocation. Finally they call IExtractImage::Extract and that’s when you generate the thumbnail.
But, after my GetLocation method returned, the application silently exited. What could be wrong? My code worked fine in Explorer.
GetLocation is a typical function that takes a character string buffer and length along with some other parameters (omitted here):
I noticed that this other app was giving me an unusually large file pathname buffer, 520 characters or 1040 bytes to be exact. This number sounded strangely familiar (and not just because of this).
Then I realized what happened. I’ve never seen the source code for this app I was crashing, but I just know it looked like this:
Oops. The cchMax argument to GetLocation is a length in characters, but sizeof gives you the size in bytes. And we’re talking WCHAR here, so each character is two bytes. MAX_PATH is 260, making szPath 520 bytes long, the number that they passed into my code.
One way to fix the problem is:
That gives correct code, but I never like seeing MAX_PATH repeated like this. sizeof is in the right spirit, actually measuring the array length instead of repeating a constant, but it measures the wrong thing, bytes instead of characters (array elements).
I like to code this with the elementsof macro, defined as:
Then you can just use elementsof instead of sizeof:
elementsof is handy anytime you need the length of a character string array or any array.
Of course, I didn’t have the luxury of fixing this code at its source (other than reporting the bug to the program’s authors). So I worked around it by checking for the bogus 520 character cchMax and cutting it back to 260 (MAX_PATH) characters.
More C#, Ruby, and Python Iterators, and JavaScript too
Making a valiant attempt to post code with my comment system (Sorry, Mike! :-(), Mike Roome points out:
The ruby example isn
Iterators in C#, Python, and Ruby
Matt Pietrek marvels at C# 2.0 iterators and dissects them right down to the CLR bytecode. I always learn something from Matt, and this whirlwind tour is no exception.
Matt says, “This was the beginning of my descent into the loopy world of C# 2.0 iterators. It took me awhile to wrap my head around them, and when I tried to explain them to other team members I got looks of total confusion.” I wonder if it would have been less confusing if Matt’s team had first been exposed to yield iterators in a language that makes them easier to use.
After using Python and Ruby, the iterators in C# feel right at home to me. They work the same in all three languages, but in Ruby and Python there’s not as much other code to get in the way of understanding them.
Let’s combine all of Matt’s examples into one, and compare the code in each language. First, in C#:
When you run that, it should print:
First
After First
0
1
2
Before Last
Last
After Last
Here’s how you would write the same code in Python:
And in Ruby, the code looks like this:
The one unfamiliar thing here may be the |name| notation, which is how a code block such as the body of a loop receives its argument. And the p statements are a kind of print statement.
This Ruby version is even more concise and equally readable once you’re comfortable with the |name| notation:
Either way, the Python and Ruby versions make it easier to see what the iterator function does and how yield interacts with the rest of the code.
You may note that the Python and Ruby versions don’t create and instantiate a SomeContainer class as the C# version does. That’s true, and it would make the code in those languages a bit longer (but still simpler than the C# code). But, if you don’t need to—and you especially don’t need to when you’re experimenting and trying to understand a radical new technique like yield iterators—why bother?